怎么估算LLM的参数量和FLOPs?推一推、测一测
本Blog适合于知道 Transformer 基础结构、但没有尝试推导过参数量和FLOPs的朋友。
edit time: 2026-03-05 17:03:20
本文的LLM基于Transformer Decoder结构,以 GPT2-XL 为例。它有以下超参数设置:
GPT2-XL
vocab_size: 50257
context_length: 1024
num_layers: 48
d_models: 1600
num_heads: 25
d_ff: 6400
实测得到的可训练参数量为 1,557,611,200 = 1.56B。
参数量实测结果
以下是使用HuggingFace Transformers库实际加载了GPT2 XL并统计可训练参数量的结果。代码见下述附录A。
==========================================================================
总参数量 params: 1,557,611,200
单位换算 1557.61M 参数 / 1.56B 参数
==========================================================================
==========================================================================
单层结构验证(以 Layer 0 为例)
==========================================================================
LayerNorm 1 : 3,200 (0.00M)
Attention QKV : 7,684,800 (7.68M)
Attention Output : 2,561,600 (2.56M)
LayerNorm 2 : 3,200 (0.00M)
FFN Input (c_fc) : 10,246,400 (10.25M)
FFN Output (c_proj) : 10,241,600 (10.24M)
Layer 0 总计 : 30,740,800 (30.74M)
最常用的参数量估算公式
可训练参数量的估算公式为:
其中 为层数 num_layers , 为维度 d_models , 为词表大小 vocab_size 。
适用于 d_ff = 4 * d_models 且多头注意力不改变整体参数大小的情况。
直接代入得到:
相比于实际值1.56B,这已经是一个非常好的估计了。
“最常用的参数量估算公式”推导
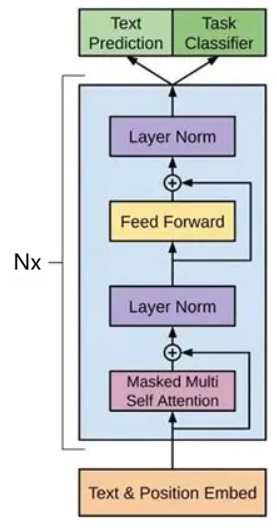
我们需要确定这个公式适用于什么情况,所以需要引入它的适用范围。
(1) Embedding
很好理解:这是Embedding层的大小,可训练参数量就是一个大小为 的二维大矩阵。并且我们在把表示换回token时,使用的LM_head权重是和Embedding共享的、而不需要额外再训练一个 ,所以它们总共只需要训练一个 。
(2) Attention & FFN
那么 又是怎么来的呢?答案就是Attention和FFN。
对于Attention,有 ,还有输出使用的 ,它们都是 的方阵,总共就是 。
对于FFN,它首先负责把维度从 扩大到 ,然后再从 缩小回 。因此前者为 ,后者是 ,总共 。
因此,一个Transformer Block内的Attention和FFN加起来应该是 。 层堆叠起来就是 。
怎么更精确地估算参数量?
(1) Layer Norm
由上可见,我们忽略了Layer Norm里面的可训练参数开销( 和 ),它们都是用于缩放的可训练向量(防止归一化不合适而添加的缩放因子),大小均为 ,所以每个 LayerNorm 应该还有 ,符合实测的 3,200 。
(2) Attention & FFN?
我们之前算下来,Attention的每个 按理来说应该是 的方阵,可实测结果是 2,561,600 ;
FFN也有类似的差距,FFN Input和FFN Output都应该是 ,可它们一个是 10,246,400 ,另一个是 10,241,600 。
相信对数字敏感的话已经知道问题在哪里了。我们估算时假定可训练参数只有 ,可这是GPT-2,不是llama等更加现代的模型,在GPT-2的时代还是有 中这个 bias 的!
加上之后马上符合事实了:
Attention输入和输出维度都是 ,所以 和 总共 正确;
FFN Input输入维度是 、输出维度是 ,所以总共 正确;
FFN Output输入维度是 、输出维度是 ,所以总共 正确。
参数量部分完结撒花!
怎么估算LLM的训练FLOPs?
参数量决定了模型的“内存占用”,而FLOPs(浮点运算次数)决定了模型的“计算成本”。
FLOPs(Floating Point Operations)指的是模型进行一次前向传播所需的浮点运算次数。对于矩阵乘法,一个 的矩阵乘以 的矩阵,FLOPs大约是 ,因为:
- 结果矩阵有 m×p 个元素,
- 每个元素由两个长度为 的向量点积得到,因此大约需要 次乘法和 次加法(共 次运算)。
下表汇总了Transformer Decoder层中各操作的FLOPs计算方式。
(记 batch_size = 1,context_length = n,维度为 ,)
| 操作 | 输入形状 | 权重形状 | 输出形状 | FLOPs计算公式 | 说明 |
|---|---|---|---|---|---|
| Attention部分 | |||||
| Q线性映射 | (n, d) | (d, d) | (n, d) | 2 × n × d × d | |
| K线性映射 | (n, d) | (d, d) | (n, d) | 2 × n × d × d | |
| V线性映射 | (n, d) | (d, d) | (n, d) | 2 × n × d × d | |
| Q·K^T | (n, d) | (d, n) | (n, n) | 2 × n × d × n | 注意力分数矩阵 |
| Attention·V | (n, n) | (n, d) | (n, d) | 2 × n × n × d | 加权求和 |
| 输出映射WO | (n, d) | (d, d) | (n, d) | 2 × n × d × d | 多头输出融合 |
| FFN部分 | |||||
| FFN第一层 | (n, d) | (d, 4d) | (n, 4d) | 2 × n × d × 4d | 维度扩展 |
| FFN第二层 | (n, 4d) | (4d, d) | (n, d) | 2 × n × 4d × d | 维度压缩 |
| 输出部分 | |||||
| LM Head | (n, d) | (d, V) | (n, V) | 2 × n × d × V | 映射到词表 |
(LayerNorm、残差连接等操作:复杂度O(dn),相比矩阵乘法可忽略)
每个Transformer块总和为 , 层总计为
其实就是之前提到的参数量 ,再多出注意力和两个矩阵乘法的额外开销 。
从而有了以下三条观察:
- Attention的上下文平方复杂度:当
context_length = n较大时, 项占主导,这使得长上下文时,Attention项成为毫无疑问的瓶颈。 - 训练 vs 推理:
- 前向传播:使用上述表格的FLOPs,即2倍训练token数乘以参数量
- 后向传播:约2倍前向FLOPs
- 总训练FLOPs ≈ 3倍前向FLOPs
- 经验公式:训练总FLOPs ≈ 6 × 参数量 × 训练token数
代入GPT2-XL参数: , , , ,
得到的前向 。
维度d增大 vs 上下文长度n增大,FLOPs瓶颈在哪里?
| 公式 | 对上下文长度n | 对维度d | |
|---|---|---|---|
| Attention的 和 | |||
| Attention其余部分,FFN,LM Head |
从上述FLOPs的公式可以看到,
随着模型大小的显著增大( 增大、 增大),Attention其余部分,FFN,LM Head将会占主导。
而随着上下文增长( 增大,或者一般常用的字母是 ),Attention的两个矩阵乘法将会占主导。
可以代入一些数据实际比较一下:
vocab_size = 50257
d_ff = 4 \times d_model
GPT-2 small (12 layers, 768 d_model, 12 heads)
GPT-2 medium (24 layers, 1024 d_model, 16 heads)
GPT-2 large (36 layers, 1280 d_model, 20 heads)
GPT2-XL (48 layers, 1600 d_model, 25 heads)
context length: from 1024 to 16,384
以下是结果(代码见附录B)。可见,
显著增大 context length 之后,Attention两个乘法(红色部分)马上成为了所有模型的绝对主导。
而在相同的context length情况下,随着模型增大,其余部分比Attention两个乘法增大得快一些(绿色占比上升,红色占比下降)。
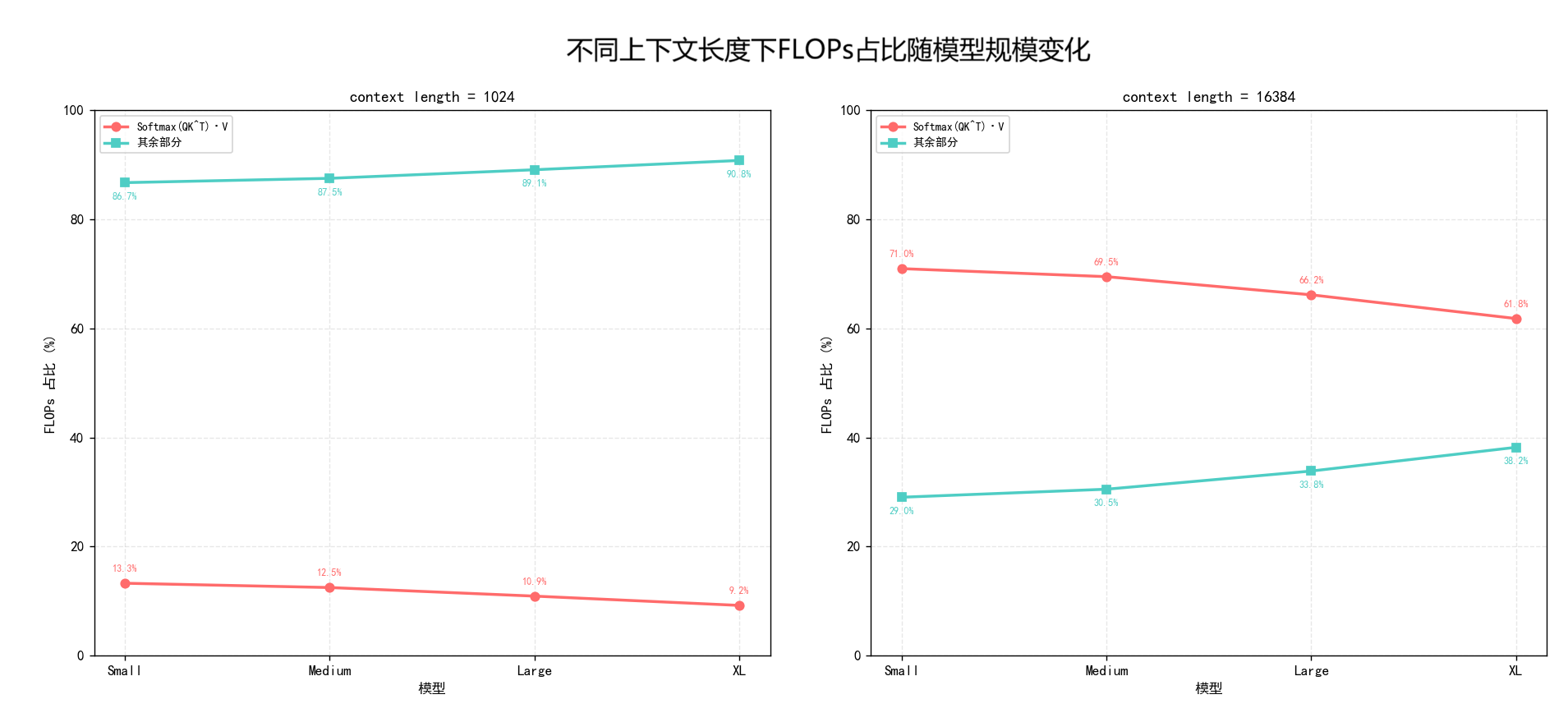
| 模型 | N | d | context length n | (A) | (B) | 总FLOPs (A+B) | A占比 | B占比 |
|---|---|---|---|---|---|---|---|---|
| GPT-2 small | 12 | 768 | 1,024 | 3.87e+10 | 2.53e+11 | 2.92e+11 | 13.3% | 86.7% |
| GPT-2 small | 12 | 768 | 16,384 | 9.90e+12 | 4.05e+12 | 1.39e+13 | 71.0% | 29.0% |
| GPT-2 medium | 24 | 1024 | 1,024 | 1.03e+11 | 7.24e+11 | 8.27e+11 | 12.5% | 87.5% |
| GPT-2 medium | 24 | 1024 | 16,384 | 2.64e+13 | 1.16e+13 | 3.80e+13 | 69.5% | 30.5% |
| GPT-2 large | 36 | 1280 | 1,024 | 1.93e+11 | 1.58e+12 | 1.77e+12 | 10.9% | 89.1% |
| GPT-2 large | 36 | 1280 | 16,384 | 4.95e+13 | 2.53e+13 | 7.48e+13 | 66.2% | 33.8% |
| GPT-2 XL | 48 | 1600 | 1,024 | 3.22e+11 | 3.18e+12 | 3.51e+12 | 9.2% | 90.8% |
| GPT-2 XL | 48 | 1600 | 16,384 | 8.25e+13 | 5.10e+13 | 1.33e+14 | 61.8% | 38.2% |
附录A: “参数量实测结果”使用的代码
from transformers import GPT2LMHeadModel
import torch
from collections import defaultdict
# 加载模型
print("正在加载 GPT-2 XL 模型...")
model = GPT2LMHeadModel.from_pretrained('gpt2-xl')
print("加载完成!\n")
print("="*80)
print("GPT-2 XL 按层参数量统计")
print("="*80)
# 统计各层参数量
layer_params = defaultdict(int)
total_params = 0
# 按参数名分类统计
for name, param in model.named_parameters():
params = param.numel()
total_params += params
# 解析层级
if name.startswith('transformer.h.'):
# 提取层号,格式如:transformer.h.0.attn.c_attn.weight
parts = name.split('.')
layer_num = parts[2] # '0', '1', '2', ...
layer_name = f"Layer {layer_num}"
# 进一步细分是 attention 还是 mlp
if 'attn' in name:
if 'c_attn' in name:
sub_type = " ├─ Attention QKV (c_attn)"
elif 'c_proj' in name:
sub_type = " ├─ Attention Output (c_proj)"
else:
sub_type = " ├─ Attention Other"
elif 'mlp' in name:
if 'c_fc' in name:
sub_type = " ├─ FFN Input (c_fc)"
elif 'c_proj' in name:
sub_type = " ├─ FFN Output (c_proj)"
else:
sub_type = " ├─ FFN Other"
elif 'ln_' in name:
if 'ln_1' in name:
sub_type = " ├─ LayerNorm 1 (pre-attention)"
elif 'ln_2' in name:
sub_type = " ├─ LayerNorm 2 (pre-ffn)"
else:
sub_type = " ├─ LayerNorm Other"
else:
sub_type = " ├─ Other"
print(f"{layer_name:10s} {sub_type:35s} {name:40s} params: {params:10,d}")
layer_params[f"Layer {layer_num} Total"] += params
elif 'transformer.wte' in name:
print(f"{'Embedding':10s} {' └─ Token Embedding':35s} {name:40s} params: {params:10,d}")
layer_params['Embedding'] += params
elif 'transformer.wpe' in name:
print(f"{'Embedding':10s} {' └─ Position Embedding':35s} {name:40s} params: {params:10,d}")
layer_params['Embedding'] += params
elif 'transformer.ln_f' in name:
print(f"{'Final':10s} {' └─ Final LayerNorm':35s} {name:40s} params: {params:10,d}")
layer_params['Final Norm'] += params
elif 'lm_head' in name:
print(f"{'LM Head':10s} {' └─ Language Model Head':35s} {name:40s} params: {params:10,d}")
layer_params['LM Head'] += params
else:
print(f"{'Other':10s} {' └─':35s} {name:40s} params: {params:10,d}")
layer_params['Other'] += params
print("\n" + "="*80)
print("各层总参数汇总")
print("="*80)
# 按层汇总
for layer_name in sorted(layer_params.keys()):
params = layer_params[layer_name]
percentage = (params / total_params) * 100
print(f"{layer_name:20s} params: {params:12,d} ({params/1e6:.2f}M) {percentage:.1f}%")
print("\n" + "="*80)
print(f"{'总参数量':20s} params: {total_params:12,d}")
print(f"{'单位换算':20s} {total_params/1e6:.2f}M 参数 / {total_params/1e9:.2f}B 参数")
print("="*80)
# 验证单层参数量是否匹配理论计算
print("\n" + "="*80)
print("单层结构验证(以 Layer 0 为例)")
print("="*80)
# 计算第一层的详细结构
layer_0_params = defaultdict(int)
for name, param in model.named_parameters():
if name.startswith('transformer.h.0.'):
if 'attn.c_attn' in name:
layer_0_params['Attention QKV'] += param.numel()
elif 'attn.c_proj' in name:
layer_0_params['Attention Output'] += param.numel()
elif 'mlp.c_fc' in name:
layer_0_params['FFN Input (c_fc)'] += param.numel()
elif 'mlp.c_proj' in name:
layer_0_params['FFN Output (c_proj)'] += param.numel()
elif 'ln_1' in name:
layer_0_params['LayerNorm 1'] += param.numel()
elif 'ln_2' in name:
layer_0_params['LayerNorm 2'] += param.numel()
for comp, params in layer_0_params.items():
print(f"{comp:25s}: {params:10,d} ({params/1e6:.2f}M)")
layer_0_total = sum(layer_0_params.values())
print(f"{'Layer 0 总计':25s}: {layer_0_total:10,d} ({layer_0_total/1e6:.2f}M)")
# 验证是否与理论计算一致
print(f"\n理论计算值: 30.72M")
print(f"实际统计值: {layer_0_total/1e6:.2f}M")
print(f"差异: {abs(30.72 - layer_0_total/1e6):.2f}M")
附录B: “维度d增大 vs 上下文长度n增大,FLOPs瓶颈在哪里”使用的代码
import numpy as np
# 模型配置
models = [
{"name": "GPT-2 small", "N": 12, "d": 768},
{"name": "GPT-2 medium", "N": 24, "d": 1024},
{"name": "GPT-2 large", "N": 36, "d": 1280},
{"name": "GPT-2 XL", "N": 48, "d": 1600},
]
# 固定参数
vocab_size = 50257
context_lengths = [1024, 16384]
def calculate_flops(N, d, n, V):
"""
计算FLOPs
A = 4Nn²d (Attention的QK^T和Attention·V)
B = 2n(12Nd² + Vd) (Attention其余部分 + FFN + LM Head)
"""
# 计算A: 4Nn²d
A = 4 * N * (n ** 2) * d
# 计算B: 2n(12Nd² + Vd)
B = 2 * n * (12 * N * (d ** 2) + V * d)
total = A + B
return {
"A": A,
"B": B,
"total": total,
"A_ratio": A / total * 100,
"B_ratio": B / total * 100
}
# 生成Markdown表格
print("| 模型 | N | d | context length n | $4Nn^2d$ (A) | $2n(12Nd^2+Vd)$ (B) | 总FLOPs (A+B) | A占比 | B占比 |")
print("|------|---|---|-------------------|--------------|---------------------|---------------|-------|-------|")
for model in models:
for n in context_lengths:
result = calculate_flops(model["N"], model["d"], n, vocab_size)
# 格式化数字为科学计数法
A_str = f"{result['A']:.2e}"
B_str = f"{result['B']:.2e}"
total_str = f"{result['total']:.2e}"
print(f"| {model['name']} | {model['N']} | {model['d']} | {n:,} | {A_str} | {B_str} | {total_str} | {result['A_ratio']:.1f}% | {result['B_ratio']:.1f}% |")
# 打印详细数值(可选)
print("\n## 详细数值\n")
for model in models:
for n in context_lengths:
result = calculate_flops(model["N"], model["d"], n, vocab_size)
print(f"\n{model['name']}, n={n}:")
print(f" A = 4 × {model['N']} × {n}² × {model['d']} = {result['A']:.2e}")
print(f" B = 2 × {n} × (12 × {model['N']} × {model['d']}² + {vocab_size} × {model['d']}) = {result['B']:.2e}")
print(f" Total = {result['total']:.2e}")
print(f" A占比 = {result['A_ratio']:.1f}%, B占比 = {result['B_ratio']:.1f}%")