用 pilog 搭建像素风博客
一套个人自制的轻量静态博客框架:读取 blogs/ 目录下的 Markdown,生成卡片 / 清单 / 图谱三种视图,主题复刻 Chrome 断网页的像素美学。
一套个人自制的轻量静态博客框架:读取 blogs/ 目录下的 Markdown,生成卡片 / 清单 / 图谱三种视图,主题复刻 Chrome 断网页的像素美学。
总结:FlashAttention用于降低Attention计算阶段预存的显存消耗(内部计算范畴), PagedAttention用于高效管理推理的KV Cache(外部推理范畴)。 FlashAttention: 问题:标准 Attention 需要存储 N×N 的中间矩阵,显存 O(N²) 解决:分块 + 在线 softmax,显存降到 O(N) 关键:外循环 Q 块,内循环 K、V 块,在线更新 m、l、O PagedAttention: 问题:预分配连续显存导致大量浪费(内部碎片 + 外部碎片)…

因为想学一下低音谱号,顺便再多熟练熟练不熟悉的高音谱号的读谱,所以做了个小玩具出来。 把谱面难度调低还挺好玩的 → notegotya
撰写了原始的softmax、数值稳定的softmax、在线softmax的公式及其简单代码呈现。 我们讨论的起点是原始的softmax形式: $$pj = \frac{e^{zj}}{\sumk e^{zk}}.$$ 为保证数值稳定,令 m := \maxk zk, 则 softmax 可等价改写为数值稳定的softmax形式: pj = \frac{e^{zj - m}}{\sumk e^{zk - m}}. 其实就是给分子分母的 $z$ 先减去 $m$ ,然后再使用exp函数,相当于给 $pj$…
在线阅读: MLSys 中文翻译 搞到网页上方便阅读。 原网页链接: MLSys 课程名称:复旦大学2025-2026春机器学习系统课程(尚笠老师)
本部分适合于知道AdamW更新流程、但没有尝试推导过peak memory和计算量、计算时间的朋友。 A{per\layer} ≈ 9BLd + 2BhL^2 C ≈ 6 × P × D Problem (adamwAccounting): Resource accounting for training with AdamW 接下来我们计算一下使用AdamW需要多少内存和计算。tensor一律使用float32。 (a) 运行AdamW的peak memory是多少?…

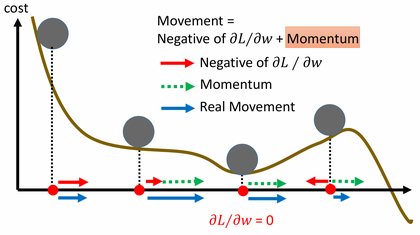
Adam = Momentum + RMSProp 本文可以省流成以下几句话: SGD往梯度下降的方向更新权重。 SGD+Momentum把梯度累积起来、得到了方向,一直同向就更新快一点,变向就慢一点。 AdaGrad把梯度的平方累积起来,让出现得频繁却梯度值很小的步长更大。 RMSProp给AdaGrad加了一个衰减系数,不看整个历史、只看近期历史,防止学习率消失。 Adam = Momentum + RMSProp。 AdamW解决了在使用Adam时应该怎么做权重衰减。 $$ \theta{t+1} =…
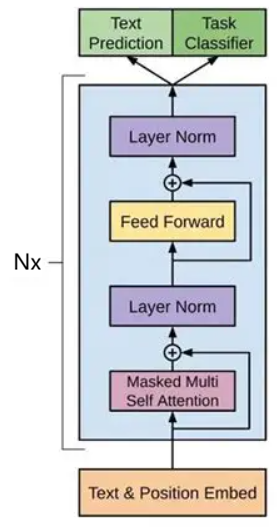
从分词开始,搭建起Transformer架构。 BPE tokenizer Transformer LM The cross-entropy loss function and the AdamW optimizer The training loop (support: serilizing, loading model, optimizer state) 4.1 Cross-entropy loss 实现交叉熵损失。 4.2 The SGD Optimizer 基础的随机梯度下降优化器的原理。 4.3…

已经搭建起了训练循环,接下来做一些实验。训得有多快?有多好? 之前的实现接口不是很好用,更进一步包装了一下,并麻烦GPT帮我优化了naive实现。 由于 testtokenizer 中 import resource 这个库只能在linux中使用,决定将核心代码拷贝到linux环境下进行测试。 而为了保证实现的正确性,在原来的windows环境下利用gpt撰写了 testtokenizerwindows.py 用于替换。 成功通过了所有测试。 在实际的训练过程中大约有如下的日志: 5.1 Data Loader…
命令行能够即时地做很多事情,甚至代表一种简洁而切题的计算机哲学。 为了直接进入正题,省略诸如 cd 这样的广为人知的基础指令,直接看那些显著提升体验的东西。 用于查看磁盘空间。使用场景比如训模型会保存很多中间文件,可以这样看看需要清理哪些。 比如 fuse-overlayfs 是这个实例本身的存储, shared-nvme 是它的外接可持久化存储,使用率分别为 50% 和 40% 。 至于要看哪几个文件最大,可以和 ncdu 这样的工具搭配使用。 查找关键词,关键词可以写正则。…
WanDB是一个python库/日志托管平台,帮我们详细记录并整理了训练过程中的各种参数和指标变化, 省去了需要自己详细记录日志、绘制图表的麻烦,并且可以做超参数搜索等进阶用法。 整合入训练循环的最小模板: 在W&B quickstart中提到了两款产品,我们主要使用的是前者,用于记录acc、loss、运行环境和模型权重等日志信息,并且便于做简单的绘图。 wanDB最本源的使用方式是通过 wandb.log 函数,记录 epoch, accuracy 和 loss ,只要在相关的地方把变量传给它就行。…
本Blog适合于知道 Transformer 基础结构、但没有尝试推导过参数量和FLOPs的朋友。 省流:P ≈ 12Nd^2 + Vd 本文的LLM基于Transformer Decoder结构,以 GPT2-XL 为例。它有以下超参数设置: 实测得到的可训练参数量为 1,557,611,200 = 1.56B。 以下是使用HuggingFace Transformers库实际加载了GPT2 XL并统计可训练参数量的结果。代码见下述附录A。 可训练参数量的估算公式为: $$12Nd^2+Vd$$ 其中 $N$…