【数据结构与算法1】数学篇:从几个专题审视算法课的数学部分
总而言之是噼里啪啦一些《算法导论》笔记
时间复杂度,求和公式,分治,哈希,摊还分析,在线算法与竞争分析,线性规划与单纯形法
基于复旦大学2025-2026秋软件工程专业黄橙老师“算法设计与分析”课程内容,感谢老师的辛勤付出!
相关配套书籍为《算法导论》,课程中选取了其中的大部分主干内容,不涉及过难的内容。
本文是学习过程中的两篇笔记中的第一篇(数学篇),加入了个人的理解和一些辅助学习的脚手架。
如有不妥当之处还望多指正,可以在下面评论区或者 https://github.com/Meredith2328/meredith2328.github.io 里提issues反馈。
- Lec1 复杂度的严格证明√
- Lec2 求和公式,1/n和ln n的关系整理√
- Lec2 各种分治递归求解方法及其练习√
- Lec4 哈希
和布隆过滤器的分析√ - Lec8 摊还分析√
- Lec12 在线算法及竞争性分析√
- Lec13 线性规划与单纯形法√
ps. 感觉Lec4 哈希和Lec5 布隆过滤器写得太糙了
回头可以连带简单实验和分析搞一个整体一点的小专题
Lec1 渐进复杂度
这一节大部分内容来自笔记 [[Lec1 算法基础]] 。
直觉:
- 在n很大时,f(n)的一个上界是g(n)。
- f(n)是g(n)的小量。
- (如果n的次数相同,大O符号允许相差常数加法和乘法)
定义
-
直觉图片
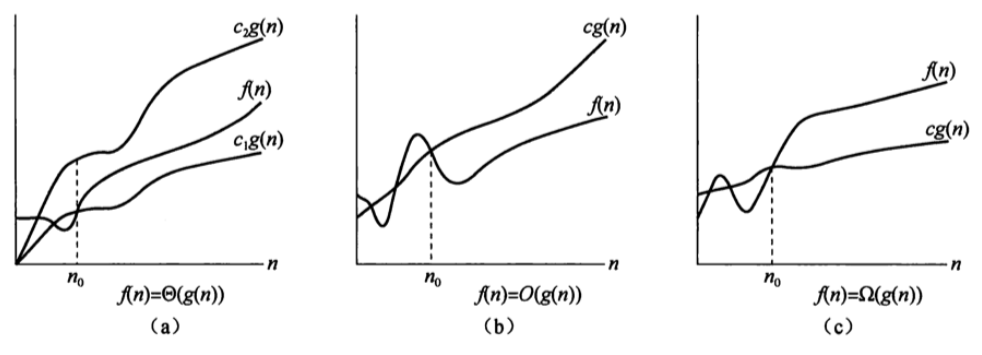
-
朴素理解:
当n很大时的上界或下界。
注意这里的等于是属于的意思,而不是等价的意思。
:渐进确界。 c1g(n)<=f(n)<=c2g(n)
:表示 的渐进上界是 ,比如最坏时间。 f(n)<=cg(n)
eg. ,但
:用来刻画“渐进下界”,比如最好时间。f(n)>=cg(n)
- 精确定义



判定的简单例子
证明:。

证明:。
直觉:当n很大时, 一定比 大。
为了证明,反设存在 使得 。
一定能推出矛盾:这个式子只对不那么大的 成立,从而对任意大不成立,推出矛盾。
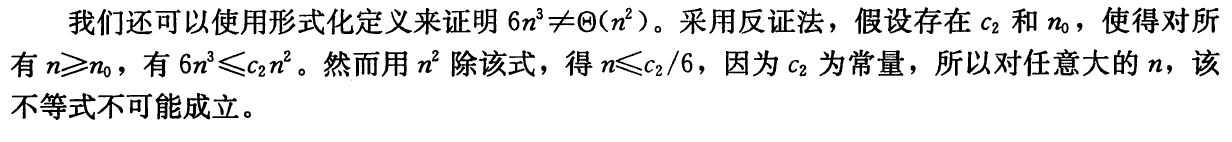

证明:。

即证明存在,当时,有。
首先证明左边。
因为,只要取得满足的,即可使成立。
即可取的任意值。
再证明右边。
因为,只要取,就有。
这符合所求的形式,即取 。
综上所述,通过取 和,原结论得证。
性质
自反性(、、),对称性(仅 ),传递性(全部五个),转置对称性。

不存在的性质:

对阶乘的额外说明
要一眼看到 和 这两种形式,就能想到它们的互相转换。
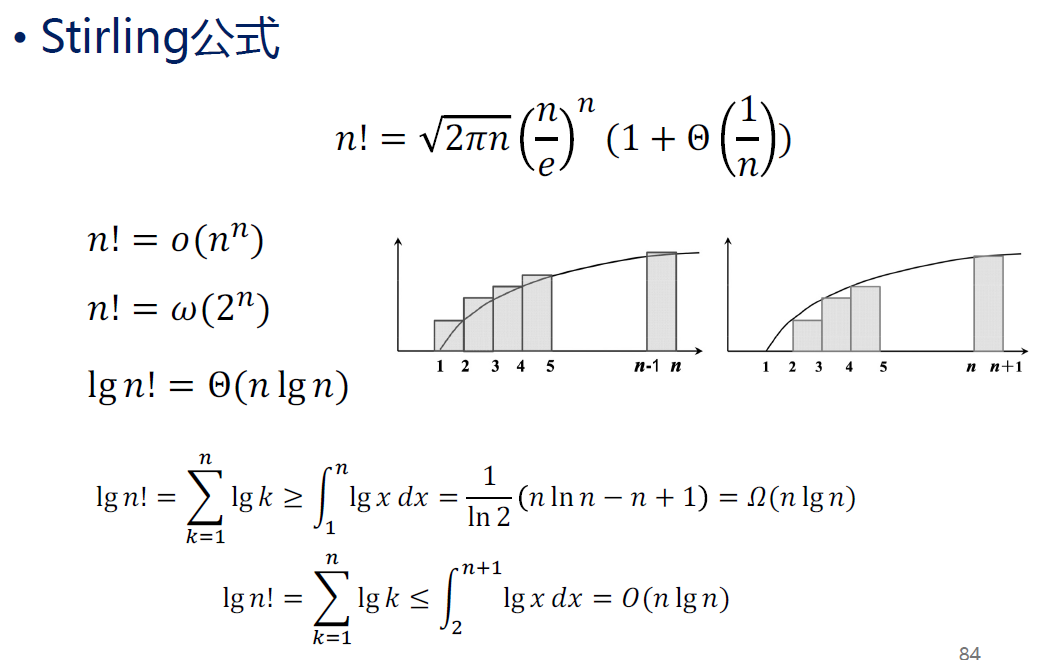
除了结论,
下面两个对数求和转积分得到复杂度也要熟练掌握:
(下界是从1到n的积分,上界是从2到n+1的积分。)
可参见下述“求和符号及其上界”部分的说明。
习题1
至少要做到能从“小量”的直觉上判断,而不是硬记那些反例。

a. 不正确。如 ,即的一个渐进上界是,但不满足。
b. 不正确。如 ,则,但。
直觉:f(n)+g(n)和min(f(n), g(n))同阶。这肯定是未必的。
c. 正确。
由有存在,对于,。
由题目条件 , 且可取得适当的 使得 ,
则有 ,即成立。
d. 不正确。
如,有,但不满足。
和c是特别好的对照。
对数把f(n)和g(n)常数乘法的差距缩小到了常数加减的差距,仍然保留大O性质。
但是指数会把常数加减的差距放大到常数乘法的差距、或者把常数乘法的差距放大到指数的差距,后者不再保留大O性质。
e. 不正确。
如,不满足。证明如下:
反设对于,有 。
选取使得 成立,
则有 ,推得与矛盾。
f. 正确。
由 可得对于,,
故对于相同的,有 ,
的渐进下确界为,即成立。
g. 不正确。
类似于d题目。设,则,根据d题目可知不成立。
h. 正确。
设,存在,使得时。
则有,取,即成立。
存在,使得时。
则有,取,即成立。
故有。
直觉:给f(n) 加了一个小量。
习题2
edit time: 2025-12-25 14:43:50

-
不正确。
直觉上,g(n)单纯是一个包装,题目要问的是f(n)<=h(n)是否有h(n)<=f(n)。
反例:
f(n)=n,g(n)=2n,h(n)=n^2。 -
不正确。
直觉上,f(n)<=g(n),h(n)<=g(n),那么f(n)和h(n)没关系。题设说h(n)<=f(n),所以反着找一个f(n)<=h(n),并且它们都<=g(n)的例子即可。
反例:
f(n)=n,h(n)=n2,g(n)=n3。 -
不正确。
f(n)=n,g(n)=2n,
0 <= 0.5g(n) <= f(n) <= g(n) ,
0 <= f(n) <= g(n) <= 2f(n)。 -
不正确。
主因是创造子元组atuple[i:j]的过程需要读取约 个元素,是 的,而不是常数执行时间。
那么再加上外面两层循环,总共应该是 了。
Lec2 求和符号及其上界
常数从1到n求和:
从1到n求和:
从1到n求和:
回顾一下等差等比公式。
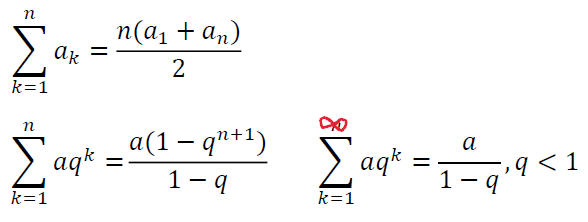
求和简单练习
DeepSeek说想到这个拆项是通过离散分部积分。 [[什么是离散分部积分]]
(没仔细检查,因为类似求和式一般化的求解并不在本课程主干内容中,先去看别的了。但是拆差分这个事情确实有点像分部积分。如果有兴趣回头可以捣鼓一下。)
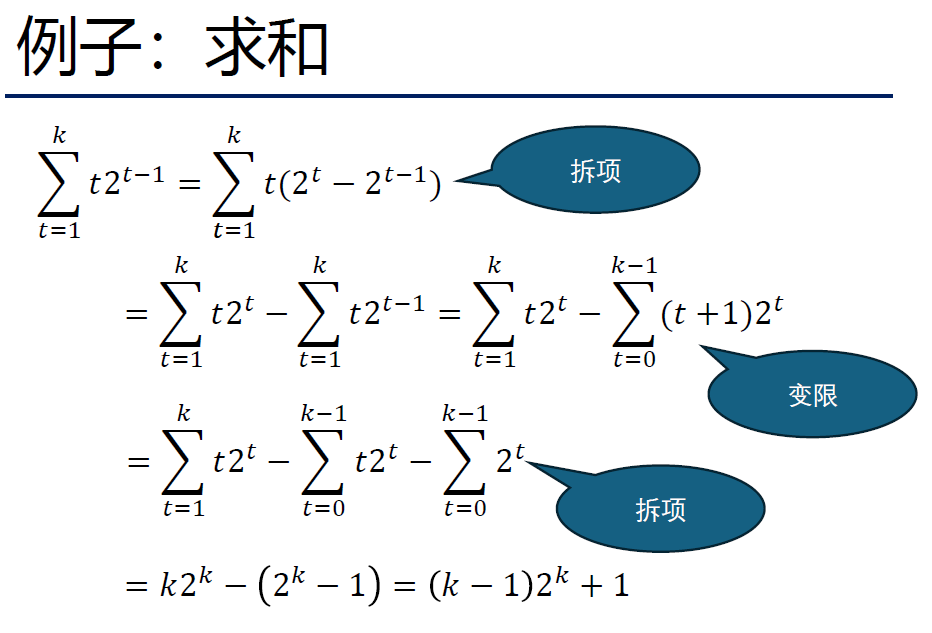
和式的上界
第一种:利用大小关系
第二种:利用比值


1/n 和 ln n的关系:用积分近似求和
总结:1/x积分一下是 ,所以1/n求和和 同阶。
详细证明可以通过积分上限多取一个、积分下限多取一个得到。
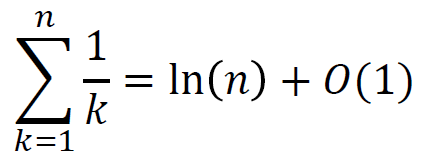
ps. 以上这个也可以作为一种调和级数发散的证明。虽然ln n发散得慢,但它也是发散的。
具体而言,有:
直觉:(积分和求和的关系)(微元法)
对于减函数 的求和式和积分式,
求和式 >= 积分上限多取一个(积分多取一个小的),
即 。
求和式 <= 积分下限多取一个(积分多取一个大的)。
即 。
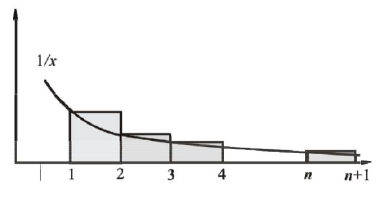
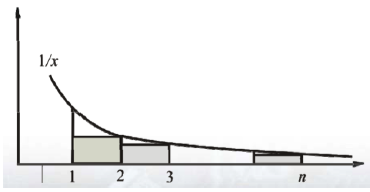
从而有以下上下界证明过程:
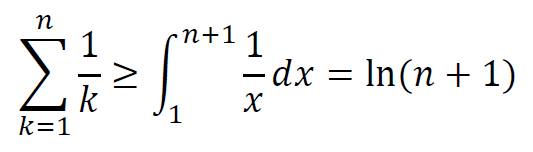
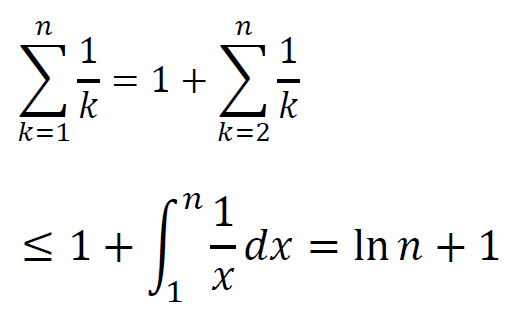
用积分近似求和
上述微元法所揭示的积分和求和的关系,还可以用于近似。
例如下式
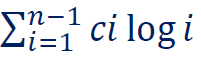
可以近似为上限多1的积分:
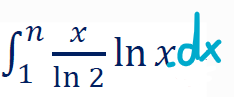
(顺便把 写成 了)
下述是后面的具体计算的说明。关键是上面,可以用积分来近似求和。
这个积分是可以积出来的,比如把x塞进dx里然后再分部积分之类的。
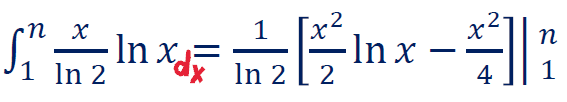
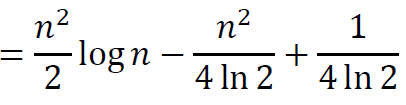
再练一下 ln n和n ln n的关系
总结:积分一下差不多是 ,所以求和和 同阶。
详细证明可以通过积分上限多取一个、积分下限多取一个得到。
递归方程的和式
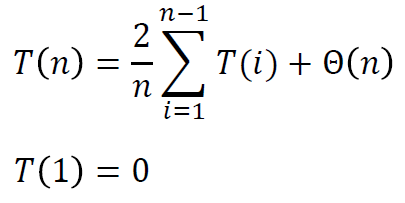
思考:
为了解上述递归方程,我们希望能够构造出两个上下限不同的和式作差。
因此,首先把 乘上去,然后变限,即可进行进一步求解。
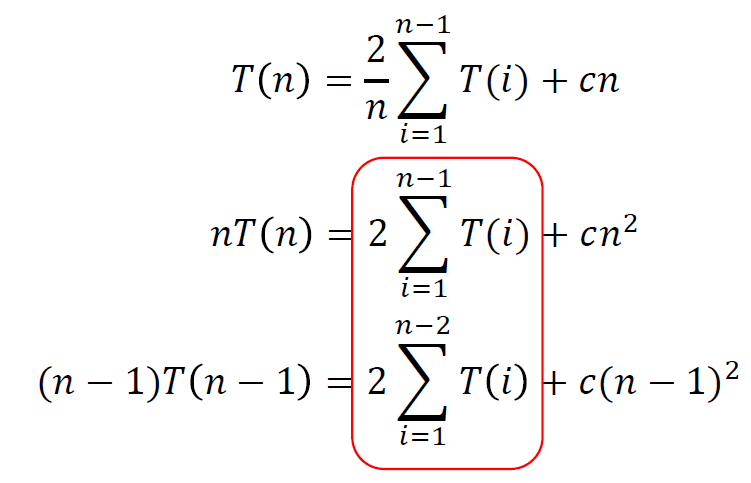

将上述递归方程的和式转换成了一个递归方程。
接下来就可以通过下述“递归方程求解的四种方法”求解了。
比如设 然后代入法解出来之类的。
Lec2 递归方程求解
四种方法:代入法、递归树、尝试法、主定理。
全部掌握。
代入法
题型:
- 两个函数参数有加减关系 (及含求和式的递归方程)
- 两个函数参数有乘除关系
也可以用数学归纳法严格证明。
例1:加减
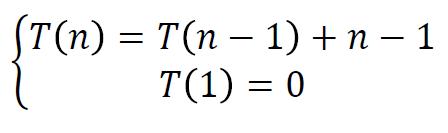
例1的解:两个变量有加减关系,直接代入。
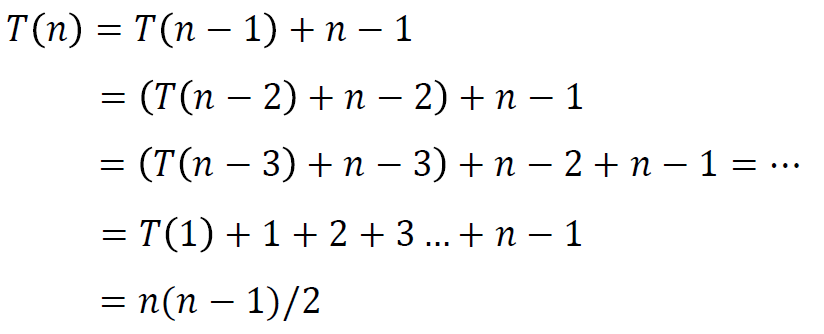
例2:比值
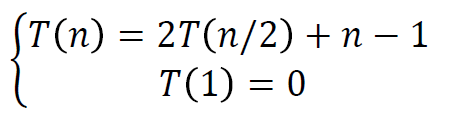
例2的解:两个变量有比值关系,需要换元到指数再代入。
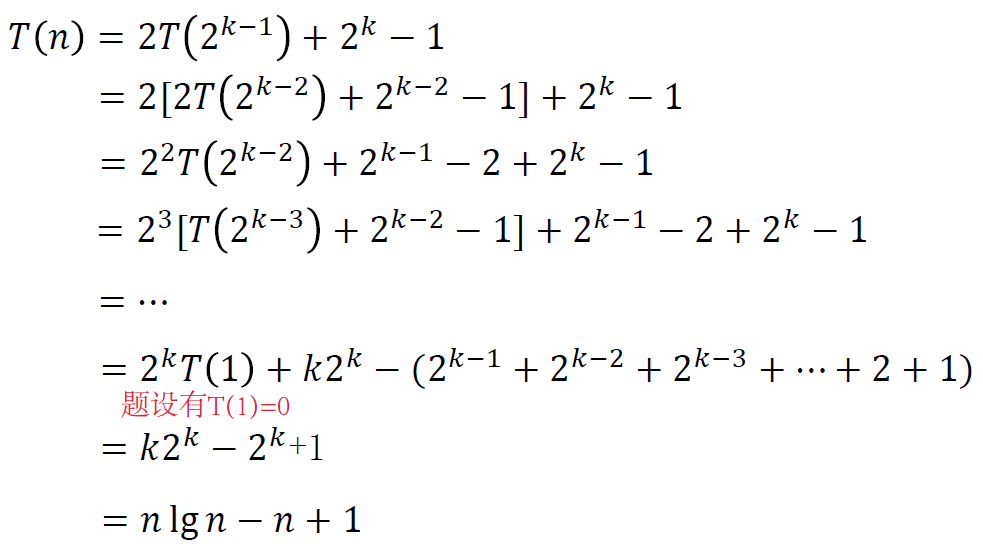
例3:如何分析快速排序的最坏情况复杂度?
解:最坏情况是分治时每次都把所有元素分到同侧,另一侧元素为空。
此时,原来问题是 的,子问题是 和 的。
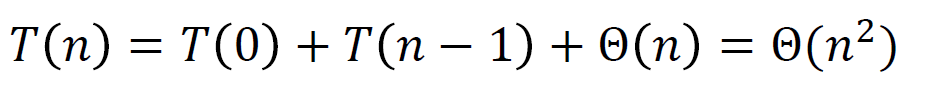
用代入法容易解出 。
例4:如何分析快速排序的平均情况复杂度?
解:分治时可能有子问题是 和 , 和 ,..., 和 共n种情况。
对于每个情况,需要进行 次比较之后把划分元素放到合理位置。
即它们的递归方程为
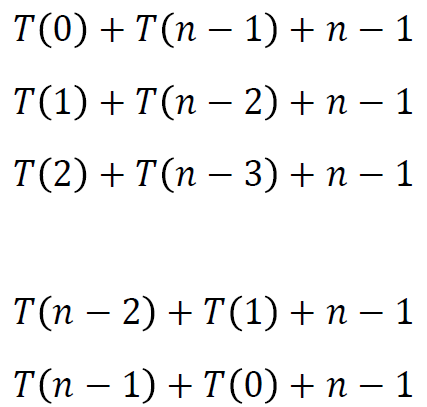
接下来假设各种情况是等概率的,总共 种情况,每种情况的概率是 。
则平均情况即将 置为期望值,为
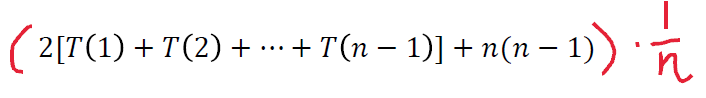
即
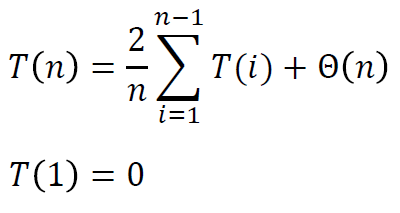
这是一个递归方程的和式,可以参见前述“求和符号及其上界-递归方程的和式”部分,通过构造不同上下限的和式进行相减,把它转化成如下递归方程。
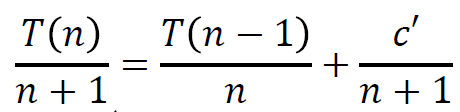
然后就可以通过代入法进行求解了。
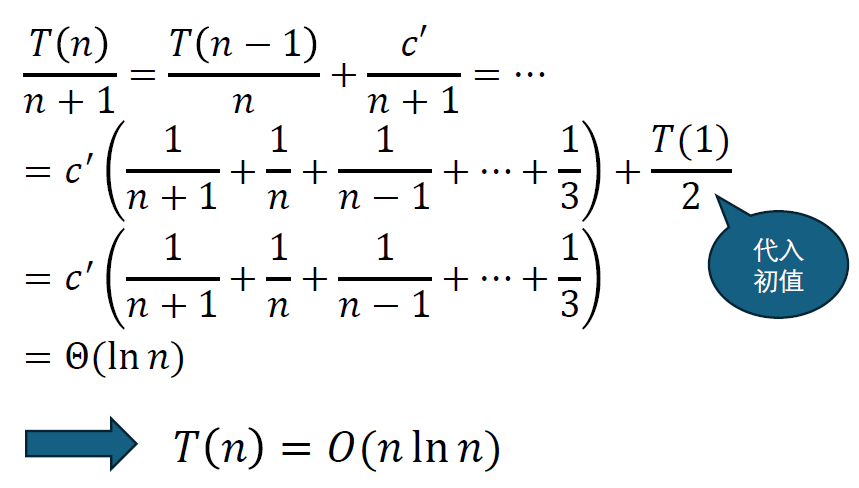
我们也可以用积分近似上述和式,直观验证我们得到的结果。
递归树
题型:比值关系
解法:
- 求每个节点的复杂度,得到每一层的复杂度
- 求树的深度,具体而言求“降低得最慢”的比值什么时候把降低到
除了代入法,也可以通过递归树求解具有比值关系的递归方程。
具体而言,
通过求 每个节点的复杂度 => 每一层的复杂度 和 树的深度,再把它们加起来,
就得到了整个递归树的复杂度,即原问题的解。
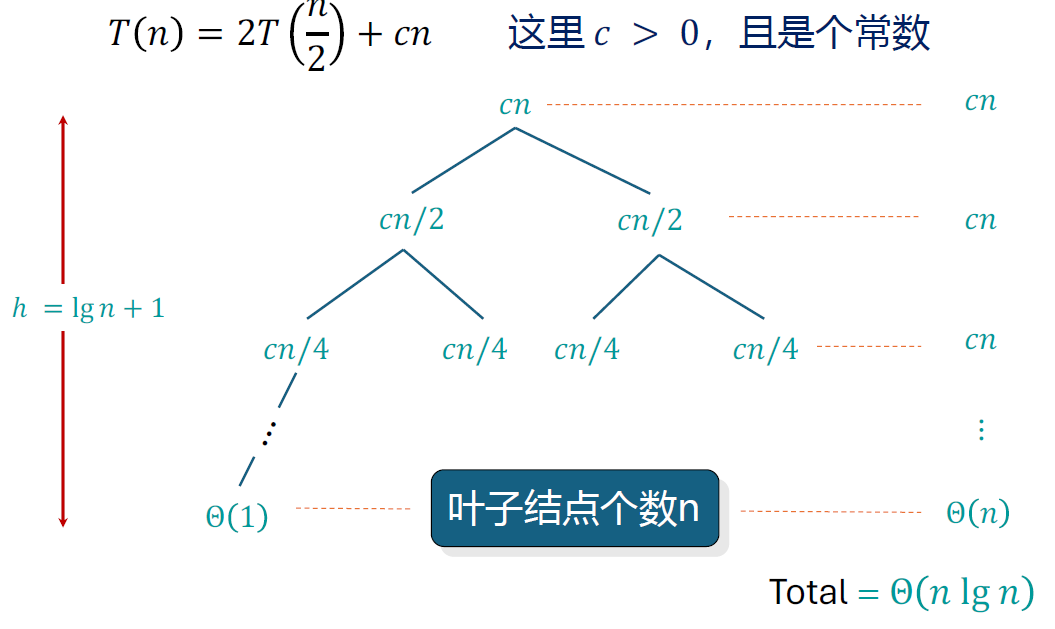
例1

例1解:
- 求每个节点 的复杂度,即 。从而求和得到每一层的复杂度,即 。
- 求树的深度,只有一个比值 ,令 得到 ,从而有 。
例2
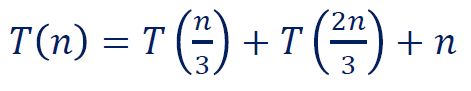
例2解:
- 求每个节点的复杂度,即 , 和 之类的。求和得到每层复杂度是 。
- 求树的深度。两个比值中把 更慢弄到 的是 ,所以 ,得到 。
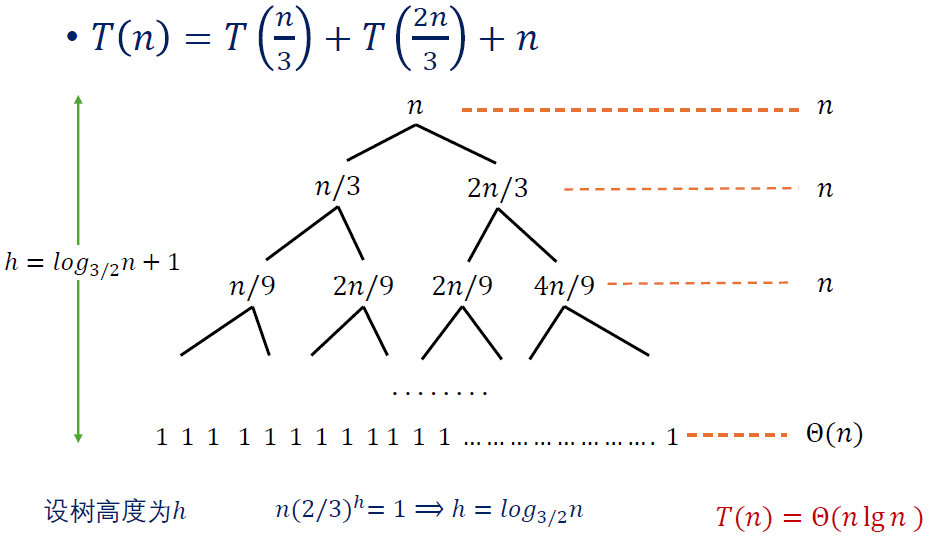
例3
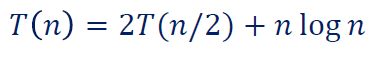
例3解:
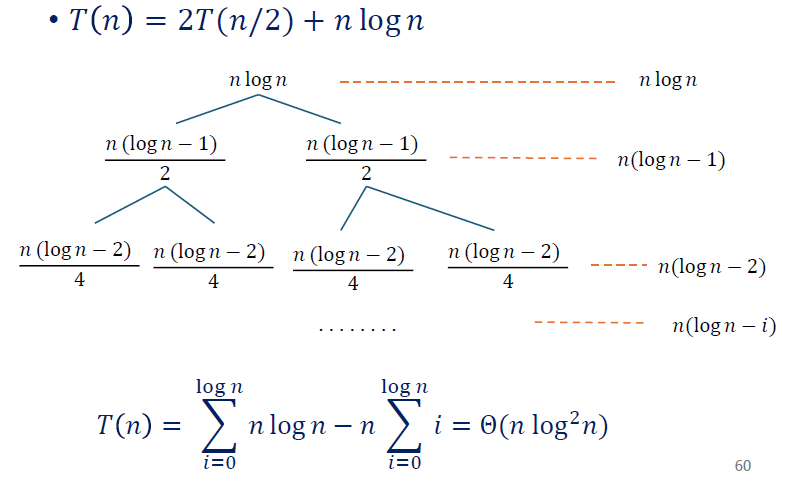
左边的求和式好解,求和内与 无关,所以直接是 。下取整不影响阶数,可以直接理解为 ,只是为了方便而额外说明。
右边的求和式可以理解成 ,从而 。项数是 ,首项是 ,尾项是 ,则求和结果为 。
一减,仍然留下来 的主项。
尝试法
题型:含求和式的递归方程,可能比代入法快,但要看你眼力如何。
假设 ,验证代入后右边确实为 的形式。
注意 需要 严格 相同 ,而不是同阶就可以了。
例1
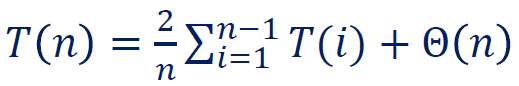
思考:
之前快排平均复杂度这道题咱们先构造了和式相减、转化成简单递归方程然后求解的。这个事情还是比较麻烦。
如果你的眼睛比较强大 ~~或者本来就知道快排的平均复杂度是 ~~,完全可以进行一个猜:假设 ,验证代入后右边确实是 。
例1解:
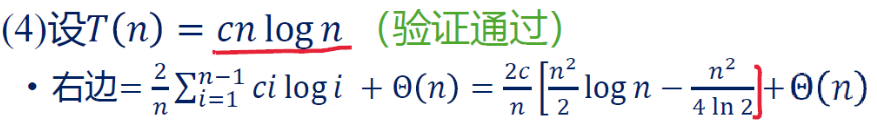
一定要注意最终得到的严格是 ,连系数 也是完全一致的。
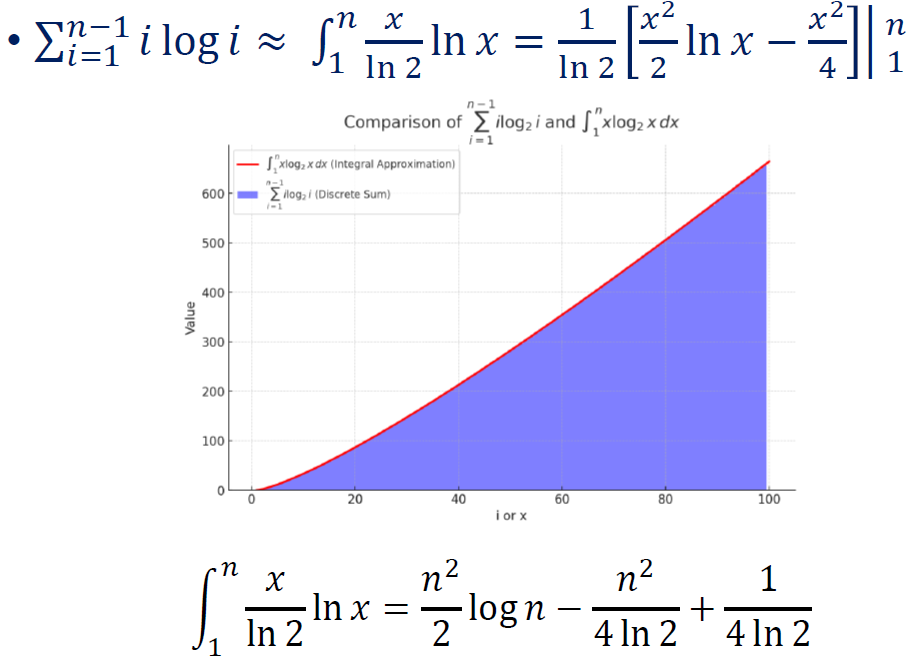
ps. 对于ilogi求和的说明,参见前述“求和符号”一章的“用积分近似求和”。
请仔细比较以下三个不成功的尝试:
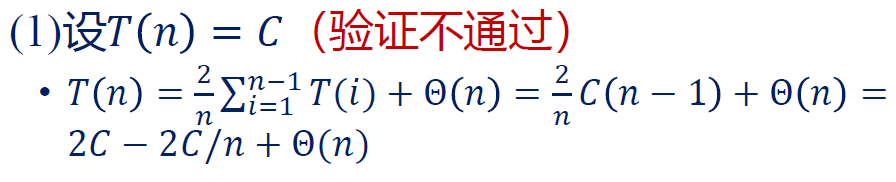
这是因为主导项是 , 和 矛盾。
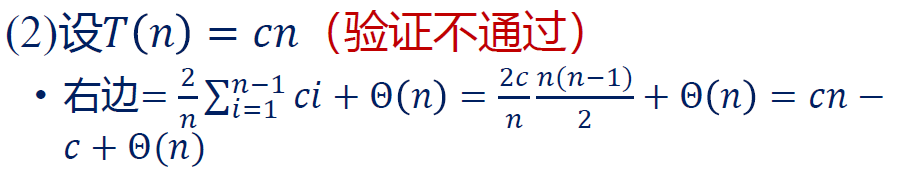
这个错误比较隐蔽,是因为系数不严格相同。
对于 ,我们设它是 ,则实际上右边是 ,和我们设的 系数对不上。右边比我们的假设增长更快,这是不允许的。
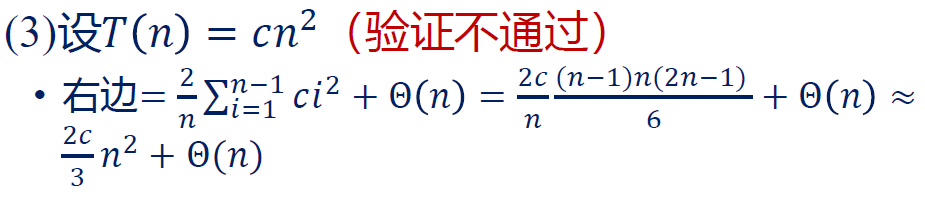
右边是 ,系数上多了一个 ,这也是不允许的。一定严格地让系数也相同。
主定理
含比值关系的递归方程。比递归树做得快,毕竟相当于直接背结论。
主要步骤是把 和 进行比较。
如果 比 增长快,而且 满足子问题总工作量比原问题小一点 (),不然主导的不是根层 了,则 是 。
如果 比 增长慢, 是 。
如果 和 增长一样快, 。

主定理证明直觉:
变 ,说明递归树深度为 ,最多进行了 次分裂。
而每个节点分裂成 个子节点,所以大致地叶子结点个数为 。
eg1.
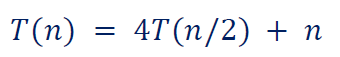
解:, ,,则 。
eg2.
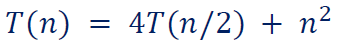
解: 。
eg3.
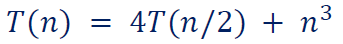
解:
首先 ,。
然后 要满足根层主导,即要求存在 , ,
即要求存在 , ,可取 。
两个条件同时满足。故 。
eg4.
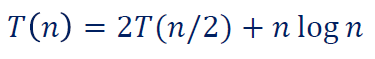
解:
先验证条件1。
, 。
首先 比 还是增长得快一点的,和都不是同阶,应该往 那个方向凑。
但是根据高数的结论, ,则不可能满足 。
从而条件1不满足,无法使用主定理进行求解。
实际上条件2也不满足:
不存在 使得 , 即 。
但是可以使用其他方式,如递归树。见递归树例3。
练习


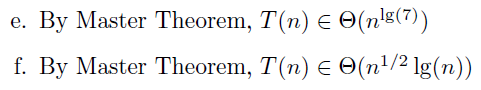
g.
拆分开的三个求和式我们都会算。所以是 。

a. 优先考虑主定理。
,取 。则有 。
b. 这道题难一些,相当于考虑 的尽量紧确的上下界。
可以利用尝试法证明,它的上界是 ,下界是 。

备注:
第一个不等式串最后:当 充分大时, 1/lg n - clg 3 <= 0肯定是有的。
第二个不等式串原书答案有笔误,上图已经修改好了。
c. 主定理, ,不解释。
d. 对于足够大的n,加减的影响远远小于乘除,所以 直接考虑成 就行。然后主定理一下就有 。
e. 和b压根就是同一道题。
f. 这里顺手写两种解法。
直觉上你可以画个递归树,从n到1减得最慢的是 那一项,贡献了 的深度。
所以整个下来就肯定是 了。
另一种解法是尝试法,目测是同阶的一堆 加起来、并且数量是指数减少的。所以设 ,则右边<=
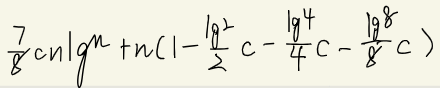
这一团在n充分大的时候肯定是 <= cnlgn的,
因为左边那个只有 7/8,右边那个是一团系数倍的n,都差个阶呢。
g. 很难忍住不代入法。1/n求和,根据积分可知肯定是 了,看不出来的话看我前面求和符号那一章。
(下面h和i算法导论答案用的方法超纲了)
h. 跟g同理,ln n求和是 这个阶的。
直觉上,n个ln n求和,子问题个数线性变少,那大概率就是给ln n乘个n了。
但是答案用弄了个很紧确的界,超出本课程范围了,看看就行。
i. 1/lg n求和,就算只取奇数项或者只取偶数项,类似h,直觉上还是 这个阶的。
j.
直觉上,我们只见过加减性和乘性的递归方程诶,这种乘方怎么办呢?
说得对!拿指数换元把它变成加减性和乘性就好了~
对于充分大的n,设 ,如果不能取整那就下取整一下之类的。
这个换元好处是,现在 ,一代入发现
再设 ,把函数换掉,则有
我们甚至还能继续化简
设 ,则有
故由主定理, ,则
再把 换回 有 。
一类考试常见题型的说明
在整理往年题时,发现这类子问题划分不均等的递归式求解比较常见。
关键是,“递归树每层子问题复杂度加起来是否与原问题相等”。
如果相等,意味着最终得到的复杂度可能阶数比 更高。
如果小于,最终得到的复杂度可能与 同阶。
具体而言,以以下例题为例。
例1
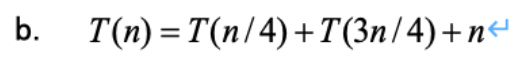
一种递归树的解法是,每一层的复杂度加起来()恰好等于 ,
深度由最大的系数 决定,是 的。(具体而言,)
则 。
ps. 求和上界含义是 <= log n的最大整数,也即 ,和是同阶的。
当然也可以用尝试法分别解得 和 ,得到相同结果。
例2
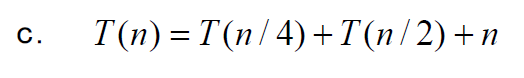
注意这里的区别:每一层的复杂度加起来()是小于 的。
具体而言,第一层加起来是n,第二层加起来是3/4n,第三层加起来是9/16n,...
尽管它的层数仍然是 的,但是因为每一层的复杂度不到 ,不像例1,整个加起来很可能不到 。
这个直觉也可以由递归树及其求和验证:
。
类似的也有以下这道题。同理,不做额外说明。
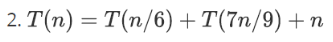
例3
这个只是一个代入法,不知道为什么写在了这里。
扩展:例1、例2的通解方法在算法导论本章的末尾有介绍,叫做Akra-Bazzi方法。
我们只要通过递归函数系数和参数系数构造方程并解出指数,
然后对进行一个积分,就可以获得 的渐进紧确界。
对于前面例2的说明,如果半信半疑,可以参考下述算法导论第4版对类似题型的Akra-Bazzi方法的讲解。






Lec3 指示器随机变量
关键是要引出新工具:指示器随机变量,对随机算法进行分析。
用于把原来的求和式转换成对随机变量的求和,从而便于求解期望。
指示器随机变量
我们首先定义指示器随机变量,用于表示“划分 ”。

接下来分析这个随机变量单个的期望。
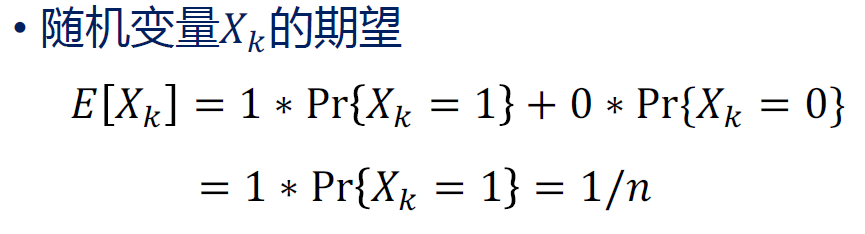
再接下来假设所有划分都是等可能的,则可以利用 帮助计算其他期望。
随机快速排序分析
下述是随机快速排序最坏情况的递归式的各种情况,
它假设了第𝑖个元素总是落在分区的较大一侧(上界)得到以下这些式子。
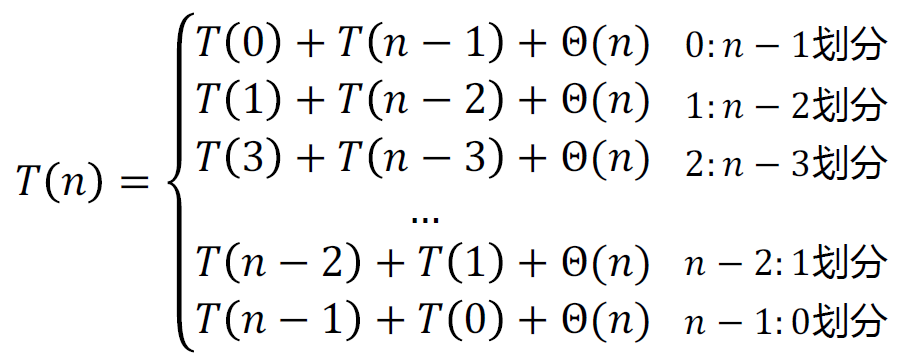
为了求 的期望,我们需要把所有n种情况统一在一个求和式里。
这是通过上述随机变量实现的。

接下来 就也是一个随机变量了,可以对它求期望。
使用期望的性质,以及 与其他随机选择相互独立的性质,有

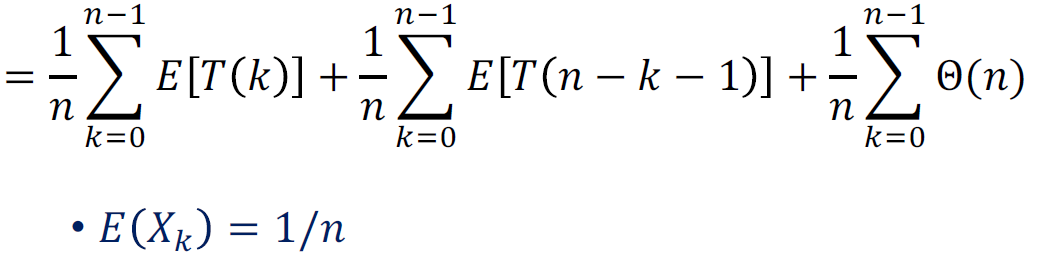

(前两个求和式其实是同一个,只不过一个是从0往n-1加,一个是从n-1往0加)
化简即得
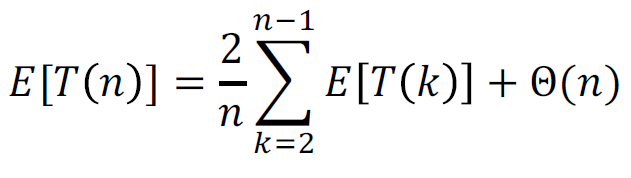
我们可以利用第二类数学归纳法处理这个期望递归式,证明它是 。
关键是,随机快速排序T(n)最坏情况的期望是,
这是好于一般的快速排序最坏情况为 的。
细节见下。

随机快速选择分析
每个情况比随机快速排序少个子问题,只剩一个子问题。
毕竟随机快速选择我们只要一直往要选的那个元素那边走就行,另外一半不需要管。

求期望有

应该可以类似地使用第二类数学归纳法进行证明。我没有详细尝试过。
总之随机快速选择算法最坏情况是 的,期望是 的。
Lec4 哈希
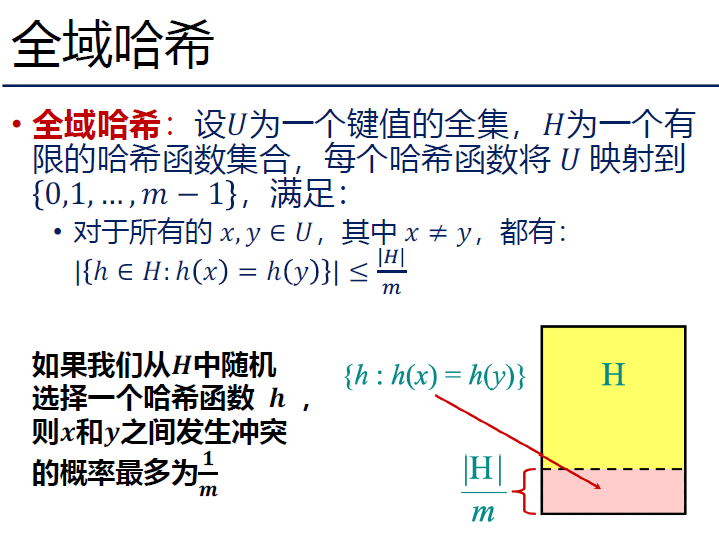
全域哈希
直觉很简单:
对于确定的哈希函数,可以构造很坏的输入,使得这个哈希函数冲突严重。
因此选取一个哈希函数族,随机从其中选择某个哈希函数,消除最坏情况。
其余都是对这个的证明。





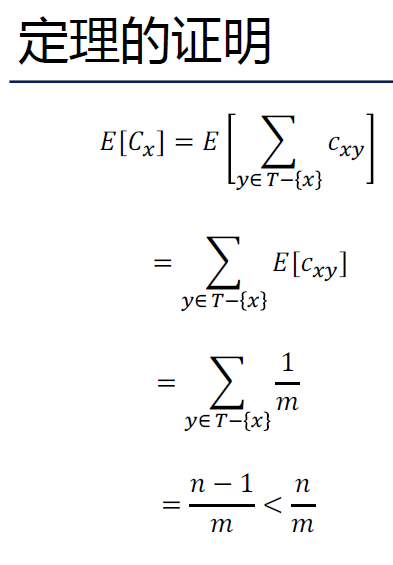



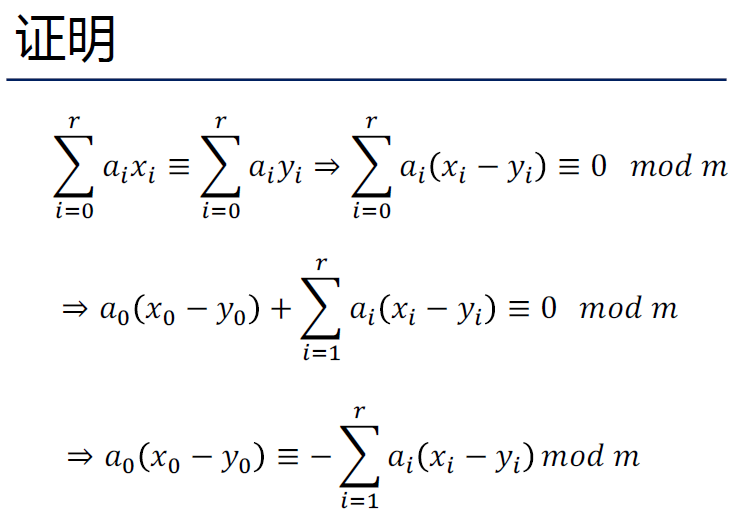


完全哈希
在全部键已知且不变的情况下,
这里的两级哈希是一种完全哈希的实现方式,
能保证 查找、无冲突、使用的空间为 。
思路是,首先用一个哈希把 个键映射到 个桶中,
然后对每个桶使用一个从全域哈希族中选出的哈希函数,再次进行哈希。
下述证明这种方式能够 查找、无冲突、使用的空间为 。
-
查找:只是进行了两次哈希。
-
无冲突


-
使用的空间为



举例:为每个桶建二级哈希表
二级表大小 mj 取 nj2 或更大,这里为了无冲突,取 mj=nj2。
桶 0 (n0=1):
- 大小 m0=1,随便一个哈希函数即可。
比如 h2,0(k)=0,键 60 放位置 0。
桶 1 (n1=2): - m1=4,需要选 h2,1 使得 10 和 52 不冲突。
尝试 h2,1(k)=(k mod 5) mod 4:- 10mod5=0 → 0
- 52mod5=2 → 2
不冲突,可以。于是表大小 4,位置 0 放 10,位置 2 放 52。
桶 2 (n2=1):
- m2=1,任意。
桶 3 (n3=1): - m3=1。
桶 4 (n4=2): - m4=4,键 72 和 89。
尝试 h2,4(k)=(kmod7)mod4:- 72mod7=2 → 2
- 89mod7=5 → 1
不冲突,可以。
桶 5、6 类似。
习题



Lec8 摊还分析
“对于长度为n的操作序列”
其实题型不多,最主要的是二进制位的这个问题
聚合法:分析每个操作的代价上界 ,从而求得总序列的
核算 法(记账法):存钱花钱
势能法:不绑定在每个操作上,而是绑定在整体能否做功上
栈操作序列
设push和pop都是O(1)的,
Multipop(S, k)即pop k次的代价为 min(|S|, k) 。
请分析n个栈操作序列的平摊代价。
(粗略分析:假设n个操作序列每个操作都是代价最大的操作的最坏情况;
精细分析:代价最大的操作可能只出现少数次)
如果粗糙地分析,每个Multipop最坏是 ,最坏情况是n个序列都是Multipop,这样的话 ,平摊代价 。
实际上,精细地分析,每个对象在压入之后最多被弹出一次,即pop数(包括在multipop内)不会超过push数。
对于长度为n的序列,最多有n次push(其实n-1也差不多,我们这里看阶数即可),从而最多有n次pop。因此,n个栈操作序列的代价 。则平摊代价 。
二进制计数器
对于n个二进制计数递增(increment)操作的序列,请分析序列的平摊代价。
设二进制计数器总位数为k。
每次操作的代价即“需要翻转的比特数”,例如从11到100需要翻转3个二进制位。
粗略分析:
代价最大的操作是 的,假设n个操作序列每个操作都是代价最大的操作的最坏情况,从而 , 。
精细分析:对于长度为n的操作序列,设二进制计数器的位数为k。
n次递增从0加到了n,需要使用位存储数。(例如16需要五位,10000)
A[0] 每1次操作发生1次改变,则n次操作发生n次改变。
A[1] 每2次操作发生1次改变,则n次操作发生n/2次改变。
A[2] ...4...n/(2^2)...
...
A[lg n] 每n次操作发生1次改变,则n次操作发生1次改变。 废话文学
故对 i = 0, 1, ..., lg n ,A[i] 发生 次改变。
(总共k位中的其余位不改变)
根据对每个位的改变的精确分析,可知
则每个递增操作的平摊代价是 。
核算法
平摊代价总和 比 实际代价总和 大。
核算法分析平摊代价:“提前付一下” “已经付过了”
你这个操作以后还会有代价,所以你多付一下

例1 栈操作序列
cost(push)=2,
cost(pop)=0,
cost(multipop)=0

例2 二进制计数器
cost(Increment)=2
势能法
与核算法不同,它将势能作为一个整体储存,
而不是将信用与数据结构中单个对象关联分开储存。
“势能”:“能够做功”
势能法定义每个操作的摊还代价是实际代价加上势差。
直觉上,如果第t个操作的势差 是正的,则摊还代价表示第i个操作多付费了,数据结构的势增加,”以后能做的功就增加“。
如果势差为负,则摊还代价表示第i个操作少付费了,势减少用于支付操作的实际代价。总实际代价是 ,
势能法定义的总摊还代价是 。
由于我们要求 ,
所以有 ,即我们定义的总平摊代价是总实际代价的一个上界,进而完成了平摊分析。
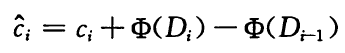
eg1 栈操作序列
定义势函数为栈的元素个数,则push操作的平摊代价是2,其余操作是0。证明如下:
定义势函数为栈的元素个数,一开始为空栈, 。
设第i个操作为push操作,此时栈中元素个数为 ,则push操作的摊还代价为实际代价加势能差,即 。(push除了操作本身,还让“pop操作能够做的功”增加了)
设第i个操作为pop操作,此时栈中元素个数为 ,则pop操作的摊还代价为实际代价加势能差,即 。
multipop同理,平摊代价为0。
(这个势函数也不是乱定义的,毕竟push和pop就会改变元素个数,所以定义为元素个数)
从而总实际代价的一个上界是我们得到的总平摊代价 。

eg2. 二进制计数器
定义势能函数为i次操作后,二进制计数器的1的个数 。
则每个Increment操作的平摊代价上界是2。
证明如下:
直觉上,设第i个操作将 个1复位为0,则第 个操作的实际代价最多为 。
例如从01111变成10000, ,实际代价为5。
第 个操作得到的势能 ,
可能是从 变成 (唯一一种情况,把所有 位全部复位),
也可能是从 变成 (复位 个1,再置位一个1的所有情况)。
则势能差为
故摊还代价=实际代价 + 势能差 得证。
动态表
聚合法:

除了一堆的1,还需要很散地加一些2、4、8等等。
n次插入的总开销 <= n + (2^j)从0加到lg n-1 <= 3n = O(n)
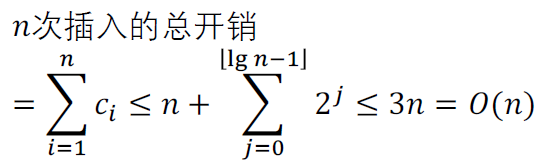
核算法:
每次插入平摊代价为3。
这是因为,当时插入需要1,移动该元素自身需要1,移动该元素的拖油瓶需要1。
随着元素增加,后面的元素还需要负责前面的元素的移动。
例如插入第5-8个元素,它们自身插入需要代价,扩容时移动它们自身需要代价,而且它们还需要负责第1-4个元素的移动。
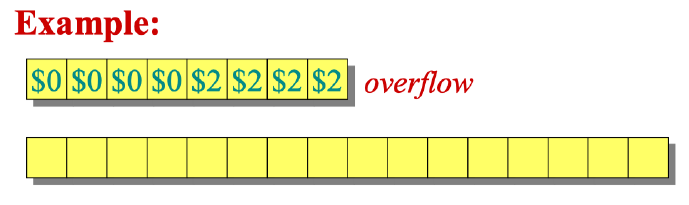
势能法原理差不多,但是过程有点繁,不写了。
习题

a.
通过一个简单数值例子说明这种数据结构,它将整个集合按照二进制划分成相应的元素个数。
查找算法:在所有划分块中进行二分查找(每个划分块内部是有序的,但划分块之间没有全局有序)。
如n=11=0b1011,
则有序数组可能为:
(满),
(空),
(满),
(满)。
数字 的二进制位表示长度为 ,即为划分块的个数。
划分块中元素为 或 ,元素最多的个数为 ,则最坏二分查找为 ,
需要查找所有的划分块,故最坏情况运行时间为 。
b.
仍然从数值例子着手,从n=11=0b1011更新到n=12=0b1100时,需要更新3位即3个数组。
最坏情况是需要更新所有数组(例如从0b0111更新到0b1000,或溢出),假设每个元素在数组中的插入和移动开销均为 ,则此时总元素个数为 ,运行时间为 。
摊还时间:使用核算法,为每个位分配2的价值,其中1的价值用于从0更新为1、1的价值用于在未来从1更新回0,则从 个元素插入到 个元素的摊还时间为 。
c.
仍然从数值例子着手,从n=11=0b1011更新到n=10=0b1010时,需要更新1位即1个数组。
如果待删除的元素在数组 中,则在 中直接删除该元素。
如果待删除的元素在数组 中,则将该元素删除后,从下标最小的满数组(记为 )中取出任一元素插入到 中并保证有序 (通过二分查找,)。则数组 仍然为满, 距离满数组差1个元素、且没有比 下标更小的满数组,满足 。再将 中的元素依次取出并添加到 中(此时自然有序,),所有数组完成更新,实现DELETE操作。

每个数组内进行检查的开销是 O(lg 2^i) = O(i) ,
最坏情况需要检查所有 个数组,
故总开销为 。
2.
元素个数为n。
- 数组个数为lg n,
- 对于数组i,大约 次插入发生一次合并,则n次插入对该数组的合并发生频率是 ,每次合并开销是 ,故对数组i的开销是 。
- 综上,聚合法求得的总开销是 ,平摊代价是 。



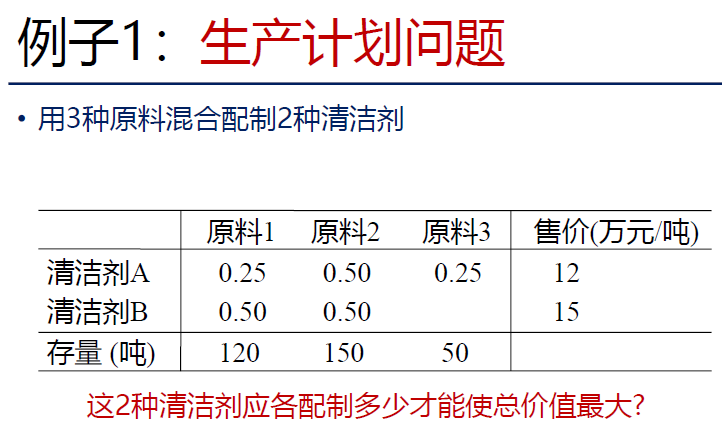
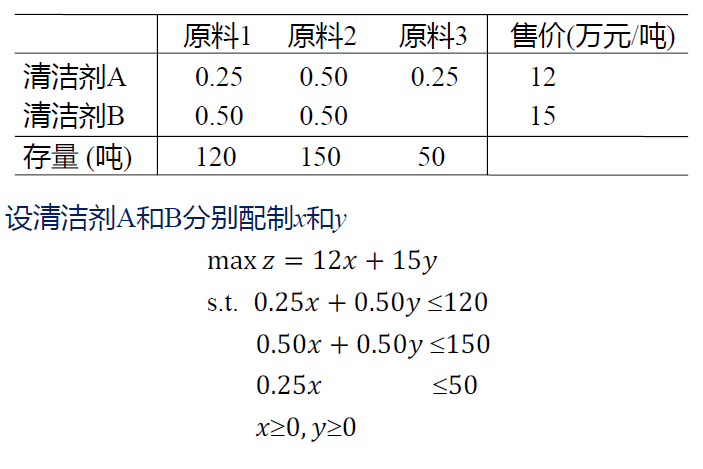
Lec13 线性规划
狠狠做题。
读题建模


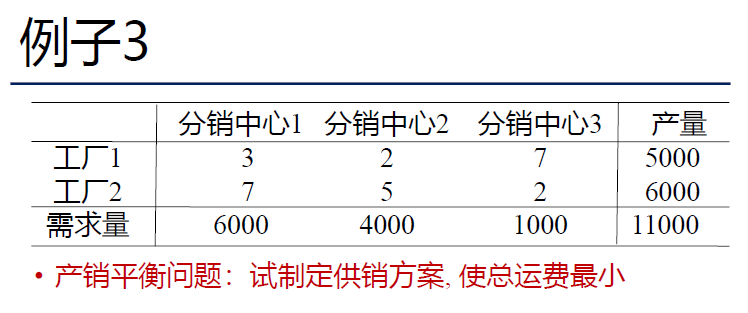

对偶单纯形法
建议只做熟两阶段法,不然条件可能会混。
步骤:
- 看 和 。
- 看 ,确定换出变量。
- 算 ,确定换入变量。
- 根据换入换出,变基,即把新基变量系数变成单位矩阵。
换出变量是b最小的变量(是哪个变量?看哪个列只有一个系数为1、其他全0!),换入变量是 比值绝对值最小的变量,
是 的值。
(其中 和 是两个向量,而我们提到的所有其他符号都是常量。)停止换入换出的两条条件要同时满足:
- b不包含负值
- 基变量包含目标函数中尽可能多的变量
eg1
eg1.
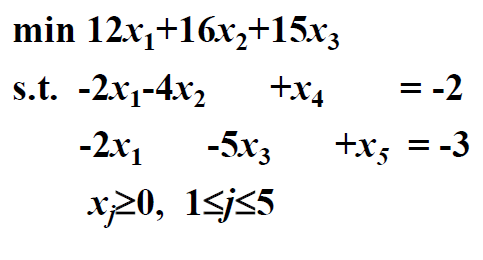
。
基变量: 和 (单位矩阵I所在的变量),此时的
- 换出变量是 。因为它的 是-3更小一点。我们只计算第二行的比值。
- 算算,lambda 1 = 12-(-2, 2)bia ji(0, 0) =12,则lambda 1/a1 = -6;lambda 2 = 16-(-4, 0)bia ji(0, 0) = 16,则lambda 2/a2 = 超大;lambda 3 = 15 - (0, -5)bia ji(0, 0) = 15,则lambda 3/a3 = -3。那 很小了,换入 。
进行一个矩阵初等变换。
| x1 | x2 | x3 | x4 | x5 | b | 行对应基变量 | |
|---|---|---|---|---|---|---|---|
| -2 | -4 | 1 | -2 | x4 | 0 | ||
| -2 | -5 | 1 | -3 | x5 | 0 |
特意记录“行对应基变量”,是为了预防一个易错点。
选 最小的变量,这里每行的 对应的是哪个变量呢?
pivot column。比如b=1对应x4(x4所在的列的主元1位于它这一行,列其余部分全0)。
而b=3/2对应x1。
而的顺序也是这样对应的。和对应的。
换出x_5,换入x_3(第二行直接除以-5,然后拿pivot搞一下单位矩阵)变成
| x1 | x2 | x3 | x4 | x5 | b | 行对应基变量 | |
|---|---|---|---|---|---|---|---|
| -2 | -4 | 1 | -2 | x4 | 0 | ||
| 2/5 | 1 | -1/5 | 3/5 | x3 | 15 |
先看再看比值。看发现我们要换出第一行的x4。
换出x4,换入x1,变成
( )
| x1 | x2 | x3 | x4 | x5 | b | 行对应基变量 | |
|---|---|---|---|---|---|---|---|
| 1 | 2 | -1/2 | 1 | x1 | 12 | ||
| -4/5 | 1 | 1/5 | -1/5 | 1/5 | x3 | 15 |
现在没有负值b了,停止。
成功把两个我们新增的变量x4,x5给换出去了。
则解为x1=1,x2=0,x3=1/5。min值为15。
eg1再练一遍。
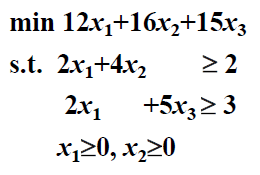
解:将其转化成min和<=得到的=。
一直有 。
| x1 | x2 | x3 | x4 | x5 | b | 基变量 | |
|---|---|---|---|---|---|---|---|
| -2 | -4 | 1 | -2 | x4 | 0 | ||
| -2 | -5 | 1 | -3 | x5 | 0 |
故换出x5,换入x3。(b取数值最小,比值取绝对值最小!)
| x1 | x2 | x3 | x4 | x5 | b | 基变量 | |
|---|---|---|---|---|---|---|---|
| -2 | -4 | 1 | -2 | x4 | 0 | ||
| 2/5 | 1 | -1/5 | 3/5 | x3 | 15 |
故换出x4,换入x1。
| x1 | x2 | x3 | x4 | x5 | b | 基变量 | |
|---|---|---|---|---|---|---|---|
| 1 | 2 | -1/2 | 1 | x4 | 12 | ||
| -4/5 | 1 | 1/5 | -1/5 | 1/5 | x3 | 15 |
b没有负值,所以换入换出停止。此时基变量为x1和x3。
最终解为除了基变量之外的变量全取0,即x1=1,x2=0,x3=1/5。
代入得原式min值为15。
eg2
再把两阶段法讲过的题都拿对偶做一遍,应该就熟了。
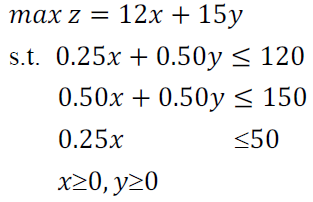
解:对偶单纯形法要全转化成min和<=,然后全转化成min和=。
原式化简一下即
化为对偶单纯形法,问题为
第一轮
| x1 | x2 | x3 | x4 | x5 | b | 基变量 | |
|---|---|---|---|---|---|---|---|
| 1 | 2 | 1 | 480 | x3 | 0 | ||
| 1 | 1 | 1 | 300 | x4 | 0 | ||
| 1 | 1 | 200 | x5 | 0 | |||
| 虽然b没问题了,但是还没有把x1和x2换入基,所以需要继续。 | |||||||
| 所以肯定换入x1了,换出x5。 |
第二轮
| x1 | x2 | x3 | x4 | x5 | b | 基变量 | |
|---|---|---|---|---|---|---|---|
| 2 | 1 | 280 | x3 | 0 | |||
| 1 | 1 | 100 | x4 | 0 | |||
| 1 | 1 | 200 | x1 | -12 | |||
| 虽然b没问题了,但是还没有把x2换入基,所以需要继续。 | |||||||
| x5之前换出过,不要再换进来了。那能换进来的就只有x2。 | |||||||
| 然后一看b,发现换出的是x4。 |
| x1 | x2 | x3 | x4 | x5 | b | 基变量 | |
|---|---|---|---|---|---|---|---|
| 1 | 80 | x3 | 0 | ||||
| 1 | 1 | 100 | x2 | -15 | |||
| 1 | 1 | 200 | x1 | -12 | |||
| 现在b全正了,而且把x1和x2都搞进来了。搞定。 | |||||||
| 最终解为 x1=200,x2=100,min值为-4100,取个反,原式max值为4100。 |
那么很大的问题来了
这玩意解出的值只是一个最值
却不一定是全局最值
实际上全局最值是180,120的4140
恭喜你浪费了很多时间去看对偶单纯形法,,
两阶段法
分两阶段:
第一阶段 设松弛变量和人工变量
优化人工变量,人工变量是每个>=和=式子需要添加的变量(<=不添加)。
要求优化结果是所有人工变量全取0。
第二阶段 设松弛变量
优化目标函数。第一/二阶段每一步做的事情:
先利用 最小确定换入变量,后利用正值最小确定换出变量。停止条件:
(第一阶段) 全部非负 且 人工变量全部换出 时停止。
(第二阶段) 全部非负 时停止。
注意两个阶段都只能选择非负最小的 ,不能选择负值 。
两个阶段只有目标函数,即 和 不同,其余的 和 全部共享。
浪费了好多时间看对偶单纯形法,气死我了
eg1
eg1
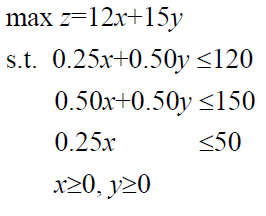
转换成标准形
min -12x1-15x2
s.t. x1+2x2+x3=480
x1+x2+x4=300
x1+x5=200
xi>=0
C=(-12, -15, 0, 0, 0)
| x1 | x2 | x3 | x4 | x5 | b | theta | |
|---|---|---|---|---|---|---|---|
| 1 | 2 | 1 | 480 | 240 | x3 | ||
| 1 | 1 | 1 | 300 | 300 | x4 | ||
| 1 | 1 | 200 | x5 | ||||
| -12 | -15 | lambda |
先lambda=c-a^TC_B最小(换入x2),然后theta=b/a绝对值最小(换出x4)
这里应该theta换出x3的,但反正最后解是对的,因为只要最后把x1和x2给换入就行,其余变量留下来谁几个不重要,,
| x1 | x2 | x3 | x4 | x5 | b | theta | ||
|---|---|---|---|---|---|---|---|---|
| -1 | 1 | -2 | -120 | 120 | x3 | 0 | ||
| 1 | 1 | 1 | 300 | 300 | x2 | -15 | ||
| 1 | 1 | 200 | 200 | x5 | 0 | |||
| 3 | lambda |
虽然lambda都为正了,但是还有x1没有换入,所以要继续
先lambda只有x1还没换入了,然后theta=b/a绝对值最小的是x3,所以x1换掉x3
| x1 | x2 | x3 | x4 | x5 | b | theta | ||
|---|---|---|---|---|---|---|---|---|
| 1 | -1 | 2 | 120 | x1 | -12 | |||
| 1 | 1 | -1 | 180 | x2 | -15 | |||
| 1 | -2 | 1 | 80 | x5 | 0 | |||
| lambda |
容易验证,现在lambda都为非负,而且x1和x2都换入了基变量。结束。
故最后的解是x1=120,x2=180,z=12*120+15*180=4140。
eg1再练一遍
解:转化成标准形
min -12x1-15x2
s.t.
x1+2x2+x3=480
x1+x2+x4=300
x1+x5=200
C=(-12,-15,0,0,0)
先看lambda再看theta。
| x1 | x2 | x3 | x4 | x5 | b | 基变量 | ||
|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 1 | 480 | x3 | 0 | 240 | ||
| 1 | 1 | 1 | 300 | x4 | 0 | 300 | ||
| 1 | 1 | 200 | x5 | 0 | ||||
| -12 | -15 |
换出x3,换入x2。
| x1 | x2 | x3 | x4 | x5 | b | 基变量 | ||
|---|---|---|---|---|---|---|---|---|
| 0.5 | 1 | 0.5 | 240 | x2 | -15 | 480 | ||
| 0.5 | -0.5 | 1 | 60 | x4 | 0 | 120 | ||
| 1 | 1 | 200 | x5 | 0 | 200 | |||
| -4.5 |
换出x4,换入x1。
| x1 | x2 | x3 | x4 | x5 | b | 基变量 | ||
|---|---|---|---|---|---|---|---|---|
| 1 | 1 | -1 | 180 | x2 | -15 | |||
| 1 | -1 | 2 | 120 | x1 | -12 | |||
| 1 | -2 | 1 | 80 | x5 | 0 | |||
容易验证此时lambda全部非负。(0, 0, 3, 9, 0),则也不需要计算theta。
则结果为x1=120,x2=180。最优值为4140。
eg2
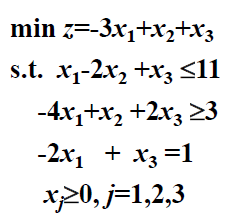
解:
min z = -3x1+x2+x3
s.t. x1-2x2+x3+x4=11
4x1-x2-2x3+x5+x6=-3
-2x1+x3+x7=1
1. 先解辅助问题,C=(0, 0, 0, 0, 0, 1, 1)。
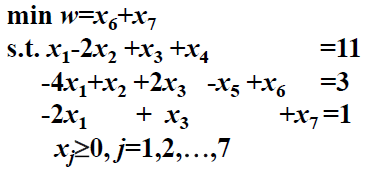
| x1 | x2 | x3 | x4 | x5 | x6 | x7 | b | 基变量 | ||
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | -2 | 1 | 1 | 11 | x4 | 0 | 11 | |||
| 4 | -1 | -2 | 1 | 1 | -3 | x6 | 1 | -3/4 | ||
| -2 | 1 | 1 | 1 | x7 | 1 | -1/2 | ||||
| -2 | 1 | 1 | 1 |
用x1换x7
| x1 | x2 | x3 | x4 | x5 | x6 | x7 | b | 基变量 | ||
|---|---|---|---|---|---|---|---|---|---|---|
| -2 | 3/2 | 1 | 1/2 | 23/2 | x4 | 0 | ||||
| -1 | 1 | 1 | 2 | -1 | x6 | 1 | 1 | |||
| 1 | -1/2 | -1/2 | -1/2 | x1 | 0 | |||||
| 1 | 0 | -1 |
用x5换x6
| x1 | x2 | x3 | x4 | x5 | x6 | x7 | b | 基变量 | ||
|---|---|---|---|---|---|---|---|---|---|---|
| -2 | 3/2 | 1 | 1/2 | 23/2 | x4 | 0 | ||||
| -1 | 1 | 1 | 2 | -1 | x5 | 0 | ||||
| 1 | -1/2 | -1/2 | -1/2 | x1 | 0 | |||||
则可取 (-1/2, 0, 0, 23/2, -1, 0, 0) 为初始解。
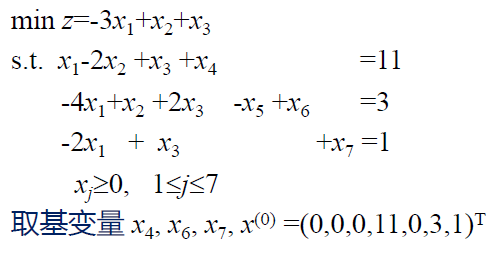
2. 解原问题,C=(-3, 1, 1, 0, 0, 0, 0)。
| x1 | x2 | x3 | x4 | x5 | b | 基变量 | ||
|---|---|---|---|---|---|---|---|---|
| -2 | 3/2 | 1 | 23/2 | x4 | 0 | 23 | ||
| -1 | 1 | -1 | x5 | 0 | ||||
| 1 | -1/2 | -1/2 | x1 | -3 | 1 | |||
用x3换x4。
| x1 | x2 | x3 | x4 | x5 | b | 基变量 | ||
|---|---|---|---|---|---|---|---|---|
| 3 | -2 | 1 | 10 | x4 | 0 | |||
| -1 | 1 | -1 | x5 | 0 | ||||
| -2 | 1 | 1 | x3 | 1 | ||||
| -1 | 1 |
eg3

eg4
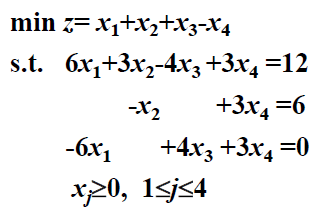
首先添加人工变量说是
C=(0,0,0,0,1,1,1),别的懒得写了
| x1 | x2 | x3 | x4 | x5 | x6 | x7 | b | 基变量 | theta | |
|---|---|---|---|---|---|---|---|---|---|---|
| 6 | 3 | -4 | 3 | 1 | 12 | x5 | 1 | 4 | ||
| -1 | 3 | 1 | 6 | x6 | 1 | 2 | ||||
| -6 | 4 | 3 | 1 | 0 | x7 | 1 | 0 | |||
| 0 | -3 | 0 | -9 |
换出x7,换入x4
(换过的不要再管了)
| x1 | x2 | x3 | x4 | x5 | x6 | x7 | b | 基变量 | theta | |
|---|---|---|---|---|---|---|---|---|---|---|
| 12 | 3 | -8 | 1 | -1 | 12 | x5 | 1 | 1 | ||
| 6 | -1 | -4 | 1 | -1 | 6 | x6 | 1 | 1 | ||
| -2 | 4/3 | 1 | 1/3 | 0 | x4 | 0 | ||||
| -18 | -2 | 12 |
换出x5,换入x1
| x1 | x2 | x3 | x4 | x5 | x6 | x7 | b | 基变量 | theta | |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 1/4 | -2/3 | 1/12 | -1/12 | 1 | x1 | 0 | |||
| -5/2 | -1/2 | 1 | -1/2 | 0 | x6 | 1 | ||||
| 1 | 1/6 | 1/6 | 2 | x4 | 0 | |||||
| 5/2 | 0 |
人工变量必须全部换出。能换入的有x2和x3,但是x3的比值无意义,所以x2换入,x6换出。
| x1 | x2 | x3 | x4 | x5 | x6 | x7 | b | 基变量 | theta | |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | -2/3 | 1/30 | 1/10 | -2/15 | 1 | x1 | 0 | |||
| 1 | 1/5 | -2/5 | 1/5 | 0 | x2 | 0 | ||||
| 1 | 1/6 | 1/6 | 2 | x4 | 0 | |||||
第一阶段结束。
C=(1,1,1,-1)
| x1 | x2 | x3 | x4 | b | 基变量 | ||
|---|---|---|---|---|---|---|---|
| 1 | -2/3 | 1 | x1 | 1 | |||
| 1 | 0 | x2 | 1 | ||||
| 1 | 2 | x4 | -1 | ||||
| 5/3 |
全部非负,并且不是人工变量那个阶段,所以停止。
取
此时
超级无敌总结!两阶段法!
第一阶段: 全部非负 且 人工变量全部换出 时停止。
第二阶段: 全部非负 时停止。
两个阶段只有目标函数,即 和 不同,其余的 和 全部共享。
edit time: 2025-12-30 11:49:07