【数据结构与算法3】基础数据结构与算法模板整理
参考:《深入浅出程序设计竞赛(基础篇)(汪楚奇)》。
(可参考:数据结构(C++模板实现))
基本上知道思路之后大部分代码都是自己完整写出来的(部分难题和跳过的题目除外),然后再补了一点细节。
往后推的同时,还需要加强巩固一些重点的专题,做做课后习题:
学过某个知识了,不代表这个知识已经掌握甚至融会贯通了。做题是为了这个目的,而不是堆数字:“增加题量”。
edit time: 2026-01-18 22:45:02 字符串、结构体专题
edit time: 2026-01-19 11:55:23 模拟专题
edit time: 2026-01-19 16:40:18 高精度专题
edit time: 2026-01-19 18:48:33 排序模板专题
edit time: 2026-01-19 20:02:17 排序练习专题
edit time: 2026-01-19 23:49:17 递推专题
edit time: 2026-01-20 12:09:54 递归专题
edit time: 2026-01-20 16:25:01 贪心证明专题
edit time: 2026-01-20 18:18:00 哈夫曼专题
edit time: 2026-01-21 02:10:40 二分查找与二分答案专题
edit time: 2026-01-21 20:58:26 搜索专题
edit time: 2026-01-21 22:56:09 栈和队列专题
edit time: 2026-01-22 16:51:47 链表专题
edit time: 2026-01-23 17:50:25 二叉树专题
edit time: 2026-01-23 21:57:25 并查集与集合专题
edit time: 2026-01-24 21:30:35 哈希的应用专题
edit time: 2026-01-27 21:31:01 图专题
edit time: 2026-01-27 21:54:06 进制转换专题
edit time: 2026-01-27 22:18:25 排列组合专题
edit time: 2026-01-27 23:41:42 整除理论专题、暴力枚举专题暂略
整本书粗略地学习了一遍,框架已经搭起来了,之后就是提熟练度了。完结撒花!!
基础篇跟进阶篇看起来有这么多东西,为什么甚至没有网络流
排错:
另外思考:算法题的测试(边界、功能)是怎么快速出出来的?
你现在已经掌握了估算数值的方法、思考递推的方法等等,还需要掌握的是:如何给自己出一些测试、从而帮助自己调出一些边界条件,而不是每次都需要全部打印出来?
- 死循环TLE:应该排查循环条件。
- Segmentation Fault和Runtime Error:排查变量是否显式初始化,循环变量对数组的访问是否处理边界,多层的循环看内层有没有写错变量名。
感悟:
- 所有变量要初始化。
- 写循环迭代时,需要注意特判、初值和边界:
- 如果不进入循环迭代,请处理相应的情况。
- 如果进入循环迭代,请保证初值正确。
- 对于比较大量的输入(如5e6),请使用 scanf 而非 cin 。
- 估算输出大小:对于 递推 等结果数值较大的问题,请使用 long long 甚至高精度。可以借助
int占4B、使用32位、最大值为2147483647来估算大小。
基础算法
模拟专题
这一部分包括三道题目(计数和方向),第一道是简单的模拟计数,第二道是经典的棋盘问题、含方向和边界处理,第三道是经典的围成圈击鼓传花。

#include <iostream>
#include <cstdio>
#include <string>
#include <cmath>
using namespace std;
char c;
string s;
int n, a, b; // a:b
int main() {
while (cin >> c) {
if (c == 'E') break;
s += c;
}
// 打印11分制
for (char ch : s) {
if (ch == 'W') a++;
else if (ch == 'L') b++;
if (max(a, b) >= 11 && abs(a - b) >= 2) {
cout << a << ':' << b << endl;
a = 0;
b = 0;
}
}
cout << a << ':' << b << endl;
a = 0;
b = 0;
cout << endl;
// 打印21分制
for (char ch : s) {
if (ch == 'W') a++;
else if (ch == 'L') b++;
if (max(a, b) >= 21 && abs(a - b) >= 2) {
cout << a << ':' << b << endl;
a = 0;
b = 0;
}
}
cout << a << ':' << b << endl;
}

// 坐标系, 以及对格子的遍历.
// 因为要遍历8个位置, 所以可以建立元素数为8的两个偏移量数组,
// 逐个位置遍历.
#include <iostream>
using namespace std;
const int dx[] = {-1, -1, -1, 0, 0, 1, 1, 1};
const int dy[] = {-1, 0, 1, -1, 1, -1, 0, 1};
const int MAXN = 105;
char g[MAXN][MAXN];
int n, m;
int main() {
cin >> n >> m;
for (int i = 1; i <= n; i++)
for (int j = 1; j <= m; j++)
cin >> g[i][j];
for (int i = 1; i <= n; i++) {
for (int j = 1; j <= m; j++) {
if (g[i][j] != '*') {
int cnt = 0;
for (int k = 0; k < 8; k++) {
if (g[i + dx[k]][j + dy[k]] == '*') {
cnt++;
}
}
cout << cnt;
} else {
cout << "*";
}
}
cout << endl;
}
return 0;
}

// 1-n. 每次传递是 cur = (cur + dir * s) % n;
// 规定逆时针遍历整个圈以排布序列, 则面向圈外时, 左手边为正方向1.
// 即 圈外1 ^ 左手0 则为正方向 dir=1, 否则为-1.
#include <iostream>
#include <cstdio>
#include <string>
using namespace std;
char name[100010][20];
int out[100010];
int main() {
int n, m;
cin >> n >> m;
for (int i = 0; i < n; i++) {
cin >> out[i] >> name[i];
}
int cur = 0;
for (int i = 0; i < m; i++) {
int a, s;
cin >> a >> s;
int dir = out[cur] ^ a;
if (dir == 0) dir = -1;
//printf("update cur from %d to %d\n", cur, cur + dir * s);
cur += dir * s;
if (cur >= n) cur -= n;
else if (cur < 0) cur += n;
}
cout << name[cur] << endl;
return 0;
}
高精度专题
本专题的三道题分别讲解了高精度加法、高精度乘法、Bigint封装。
高精度注意两次逆序:
- 写入数组时,第一次逆序写入。
- 从数组中输出时,第二次逆序输出。
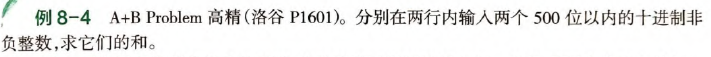
// 1. 先把输入的整数逆序.
// 2. 从低位到高位逐位相加 (循环条件是更大的位数), 得到加法与进位.
// 3. 处理边界条件: 相加时位数增加.
#include <iostream>
#include <cstdio>
#include <string>
#include <cmath>
using namespace std;
int a[510], b[510], c[510];
int main() {
string A, B;
getline(cin, A);
getline(cin, B);
int size = max(A.size(), B.size());
// 写入数组时第一次逆序
// i指向写入数组的位置, j指向原字符串的位置
for (int i = 1, j = A.size() - 1; j >= 0; i++, j--) {
a[i] = A[j] - '0';
}
for (int i = 1, j = B.size() - 1; j >= 0; i++, j--) {
b[i] = B[j] - '0';
}
// 相加, 处理进位, 并考虑size增加的情况
for (int i = 1; i <= size; i++) {
c[i + 1] += (c[i] + a[i] + b[i]) / 10;
c[i] = (c[i] + a[i] + b[i]) % 10;
}
if (c[size + 1]) size++;
// 最后输出时第二次逆序
for (int i = size; i >= 1; i--) {
cout << c[i];
}
cout << endl;
return 0;
}

乘积位数不会超过两数的位数之和。
注意“贡献”(包括乘、进位)有重叠是+=,而“保留个位”是=。
#include <iostream>
#include <cstdio>
#include <string>
#include <cmath>
using namespace std;
int a[2010], b[2010], c[4010];
int main() {
// 1. 读入并逆序.
string A, B;
cin >> A >> B;
for (int i = 1, j = A.size() - 1; j >= 0; i++, j--) {
a[i] = A[j] - '0';
}
for (int i = 1, j = B.size() - 1; j >= 0; i++, j--) {
b[i] = B[j] - '0';
}
// 首先处理乘法, 将b[j]这一位与向量a相乘, 得到对c的向量贡献
for (int j = 1; j <= B.size(); j++) {
for (int i = 1; i <= A.size(); i++) {
c[i + j - 1] += b[j] * a[i]; // 注意有重叠, 需要用+=
}
}
// 再处理进位
int sz = A.size() + B.size(); // 上界
for (int i = 1; i <= sz; i++) {
c[i + 1] += c[i] / 10;
c[i] = c[i] % 10;
}
// 3. 读出并逆序.
while (c[sz] == 0) sz--; // 去掉前导零, 引入特判: 要小心位数变为0的情况
for (int i = max(sz, 1); i >= 1; i--) {
cout << c[i];
}
cout << endl;
return 0;
}

接下来给出封装好的大整数类,在 Bigint 结构体内重载了运算符 operator[] ,在结构体外operator+ 和 operator* ,把上述两道题统一起来。
(备注:重载的写法类似于函数/方法,毕竟运算符的本质就是一个方法。右边是参数,左边是返回值。
在 operator[] 的实现中,为了能够像数组那样直接修改某一位的值,需要返回该位的引用 int& ,而不是拷贝 int 。)
#include <iostream>
#include <cstdio>
#include <cmath>
#include <cstring>
using namespace std;
// 这里的位数maxn是怎么估算出来的呢?
// 50!, 每两个数都是2位, 它们的乘积不超过4位.
// 50个数依次相乘, 从而乘积位数不会超过100位.
#define maxn 100
struct Bigint {
int len = 0, a[maxn];
Bigint(int x = 0) { // 初始值构造函数, 初始化传入的大小不超过int
memset(a, 0, sizeof(a)); // <cstring>
for (int i = 1; x; i++) {
a[i] = x % 10; // 第一次逆序写入
x /= 10;
len++;
}
}
int &operator[](int i) {
return a[i];
}
void flatten(int L) {
// 处理1-L这一段的进位 (L以上截断), 并去掉前导0.
len = L;
for (int i = 1; i <= len; i++) {
a[i + 1] += a[i] / 10;
a[i] %= 10;
}
while (!a[len]) len--;
}
void print() {
for (int i = max(len, 1); i >= 1; i--) {
printf("%d", a[i]);
}
}
};
Bigint operator+(Bigint a, Bigint b) {
Bigint c;
int len = max(a.len, b.len);
for (int i = 1; i <= len; i++) {
c[i] += a[i] + b[i];
}
c.flatten(len + 1);
return c;
}
Bigint operator*(Bigint a, int b) { // 简便起见, Bigint乘int
Bigint c;
int len = a.len;
for (int i = 1; i <= len; i++) {
c[i] = a[i] * b;
}
c.flatten(len + 11); // int<=2147483647即10位
return c;
}
int main() {
Bigint ans(0), fac(1);
int m;
cin >> m;
for (int i = 1; i <= m; i++) {
fac = fac * i; // 注意你定义的是*不是*=, 不要乱写(?
ans = ans + fac;
}
ans.print();
return 0;
}
ps. 当然,高精度还可以用字符串实现。
排序专题
知识


笔记:sort函数和unique函数(#include <algorithm>)
sort(a, a+n, cmp) 函数将数组 a 从 a[0] 到 a[n - 1] 原地排序,默认升序。
cmp 可以直接定义一个bool的元素比较函数即可。
unique(a, a+n) 函数将将数组 a 从 a[0] 到 a[n - 1] 原地去重,并且返回 &a[n] ,可以用返回值减去 a 得到去重后的元素个数。
举例

计数排序。
注意,这里是根据数组内容(计数)、输出序号。而不是常见的输出数组内容。
#include <iostream>
#include <cstdio>
using namespace std;
const int MAXN = 1010;
int a[MAXN] = {0};
int main() {
int n, m, tmp;
cin >> n >> m;
while (m--) {
cin >> tmp;
a[tmp]++;
}
for (int i = 1; i <= n; i++) {
while (a[i]--) cout << i << ' ';
}
cout << endl;
return 0;
}

选择排序、冒泡排序、插入排序。
// 选择排序:
// 每次选中最小的元素, 将其置于已排序段的末尾.
// 已排序段初始长度为0, 指针指向位置0.
for (int i = 0; i < n; i++) {
// 找到最小的元素, 将其与"空位"a[i]交换.
int maxi = i, maxval = a[i];
for (int j = i + 1; j < n; i++) {
if (a[j] < maxval) {
maxi = j;
maxval = a[j];
}
}
swap(a[i], a[maxi]);
}
// 选择排序的第二种写法.
// 遍历时, 如果相应元素更小, 则将它交换到指定为止.
for (int i = 0; i < n; i++) {
for (int j = i + 1; j < n; j++) {
if (a[j] < a[i]) swap(a[j], a[i]);
}
}
// 冒泡排序.
// 每次冒泡是从前到后的交换链, 冒泡完后保证当前最大元素交换到最后.
for (int i = 0; i < n - 1; i++) {
for (int j = 0; j < n - i - 1; j++) { // 下标边界: 来自对a[j]和"a[j+1]"的比较
if (a[j] > a[j + 1]) swap(a[j], a[j + 1]);
}
}
// 插入排序.
// 腾出空位, 将新的元素插入已排序的序列中.
for (int i = 1; i < n; i++) { // 初始a[0]已有序
int x = a[i], j = i - 1;
for (; j >= 0; j--) {
if (a[j] <= x) break;
a[j + 1] = a[j];
}
a[j + 1] = x;
}
(重点:快速排序的剪枝板子)
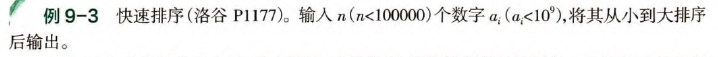
// 快速排序板子.
// 划分 + 自顶向下分治.
// 这个板子的好处是可以剪枝, 常数优化好一些,
// 而且整个代码结构超级无敌对称, 不需要一边置为<=、一边置为>。
#include <iostream>
#include <cstdio>
using namespace std;
const int MAXN = 100010;
int a[MAXN], n;
void quicksort(int l, int r) {
int i = l, j = r, x = a[(l + r) / 2];
do {
// 左边找>=的, 右边找<=的, 交换.
while (a[i] < x) i++;
while (a[j] > x) j--;
if (i <= j) {
swap(a[i], a[j]);
i++; j--;
}
} while (i <= j);
// 跳出时, i > j,
// 如果是 l j i r的关系, 则继续排[l,j]和[i,r]
if (l < j) quicksort(l, j);
if (i < r) quicksort(i, r);
}
int main() {
cin >> n;
for (int i = 0; i < n; i++) {
cin >> a[i];
}
quicksort(0, n - 1);
for (int i = 0; i < n; i++) {
cout << a[i] << ' ';
}
cout << endl;
return 0;
}
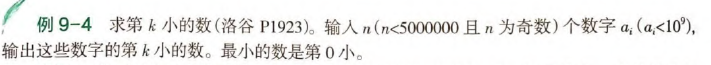
备注:注意这里MAXN = 5e6,已经很大了,读入数字请用 scanf 而非 cin ,要不然会卡常(用例5搞出1.2s左右)。
// 思想:
// 看k属于的区间.
// 每次划分后, [l, j], [j + 1, i - 1], [i, r] 三个区间相对大小有序.
// k属于其中一个区间, 通过与下标的大小关系确定.
#include <iostream>
#include <cstdio>
using namespace std;
const int MAXN = 5000010;
int a[MAXN];
int ans = 0, k;
void findkth(int l, int r) {
if (l == r) {
ans = a[l];
return;
}
int i = l, j = r, x = a[(l + r) / 2];
do {
// 左边找大的, 右边找小的
while (a[i] < x) i++;
while (a[j] > x) j--;
if (i <= j) {
swap(a[i], a[j]);
i++; j--;
}
} while (i <= j);
// 跳出条件有所区别, [l, j], [i, r]
if (k <= j) findkth(l, j); // 在[l, j]区间
else if (i <= k) findkth(i, r); // 在[i, r]区间
else findkth(j + 1, i - 1); // j < k < i, 在[j + 1, i - 1]区间
}
int main() {
int n;
cin >> n >> k;
for (int i = 0; i < n; i++) {
scanf("%d", &a[i]);
}
findkth(0, n - 1);
cout << ans << endl;
return 0;
}

(解一)范围小,所以用计数排序。
#include <iostream>
#include <cstdio>
using namespace std;
int a[1010] = {0}, cnt = 0;
int main() {
int N, tmp;
cin >> N;
for (int i = 0; i < N; i++) {
scanf("%d", &tmp);
if (a[tmp] == 0) cnt++;
a[tmp]++;
}
cout << cnt << endl;
for (int i = 1; i <= 1000; i++) {
if (a[i] != 0) cout << i << ' ';
}
return 0;
}
(解二)STL使用sort和unique函数的代码如下:
#include <iostream>
#include <cstdio>
#include <algorithm>
using namespace std;
int a[1010] = {0};
int main() {
int N, tmp;
cin >> N;
for (int i = 0; i < N; i++) {
scanf("%d", &a[i]);
}
sort(a, a + N);
int cnt = unique(a, a + N) - a;
cout << cnt << endl;
for (int i = 0; i < cnt; i++) {
cout << a[i] << ' ';
}
return 0;
}

自定义比较函数。
#include <iostream>
#include <cstdio>
#include <algorithm>
using namespace std;
struct student {
int id, chinese, math, english;
int sum() {
return chinese + math + english;
}
} stu[310];
// 降序, 大于的时候返回true
bool cmp(student a, student b) {
if (a.sum() != b.sum()) return a.sum() > b.sum();
else {
if (a.chinese != b.chinese) return a.chinese > b.chinese;
else {
return a.id < b.id;
}
}
}
int main() {
int n, c, m, e;
cin >> n;
for (int i = 0; i < n; i++) {
cin >> c >> m >> e;
stu[i].id = i + 1;
stu[i].chinese = c;
stu[i].math = m;
stu[i].english = e;
}
sort(stu, stu + n, cmp);
for (int i = 0; i < 5; i++) {
cout << stu[i].id << ' ' << stu[i].sum() << endl;
}
return 0;
}
当然,我们也可以利用之前的选择排序或插入排序,只迭代五次, :


原来已经统计完毕,直接输入的就是票数。
(我还寻思着让我计票计到100位怕是有点那什么。
可以使用高精度。不过因为输入就是字符串、而字符串自带字典序比较,所以我们可以直接复用字符串的逻辑。
但是,需要注意,字典序只能用于位数相同的数字大小比较。
#include <iostream>
#include <cstdio>
#include <string>
#include <algorithm>
using namespace std;
struct person {
int id;
string cnt;
}people[25];
bool cmp(person a, person b) { // 降序
if (a.cnt.size() != b.cnt.size()) {
return a.cnt.size() > b.cnt.size();
}
return a.cnt > b.cnt; // 字典序
}
int main() {
int n;
cin >> n;
for (int i = 0; i < n; i++) {
people[i].id = i + 1;
cin >> people[i].cnt;
}
sort(people, people + n, cmp);
cout << people[0].id << endl << people[0].cnt << endl;
return 0;
}
暴力枚举专题















递推与递归专题
- 递推和递归,要将原问题分解为子问题。递推往往考虑“最后一次”。
- 递推大概率结果很大,要用
long long甚至高精度。
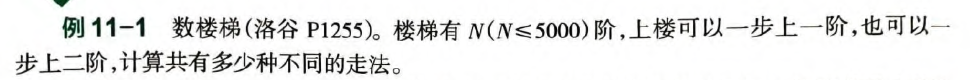
// 递推和初值
count[N] = count[N - 1] + count[N - 2]
count[1] = 1
count[2] = 2
这个递推很显然在 的数量级,因此需要高精度。
首先, 是显然的。粗略估算, ,那么 。保险起见高精度内的数组开个1600位什么的就足够了。
#include <iostream>
#include <cstdio>
#include <cmath>
#include <cstring>
using namespace std;
#define maxn 1600
struct Bigint {
int len = 0, a[maxn];
Bigint(int x = 0) { // 初始值构造函数, 初始化传入的大小不超过int
memset(a, 0, sizeof(a)); // <cstring>
for (int i = 1; x; i++) {
a[i] = x % 10; // 第一次逆序写入
x /= 10;
len++;
}
}
int &operator[](int i) {
return a[i];
}
void flatten(int L) {
// 处理1-L这一段的进位 (L以上截断), 并去掉前导0.
len = L;
for (int i = 1; i <= len; i++) {
a[i + 1] += a[i] / 10;
a[i] %= 10;
}
while (!a[len]) len--;
}
void print() {
for (int i = max(len, 1); i >= 1; i--) {
printf("%d", a[i]);
}
}
};
Bigint operator+(Bigint a, Bigint b) {
Bigint c;
int len = max(a.len, b.len);
for (int i = 1; i <= len; i++) {
c[i] += a[i] + b[i];
}
c.flatten(len + 1);
return c;
}
Bigint operator*(Bigint a, int b) { // 简便起见, Bigint乘int
Bigint c;
int len = a.len;
for (int i = 1; i <= len; i++) {
c[i] = a[i] * b;
}
c.flatten(len + 11); // int<=2147483647即10位
return c;
}
int main() {
int n;
cin >> n;
Bigint count[5010];
count[1] = 1;
count[2] = 2;
for (int i = 3; i <= n; i++) {
count[i] = count[i - 1] + count[i - 2];
}
count[n].print();
return 0;
}
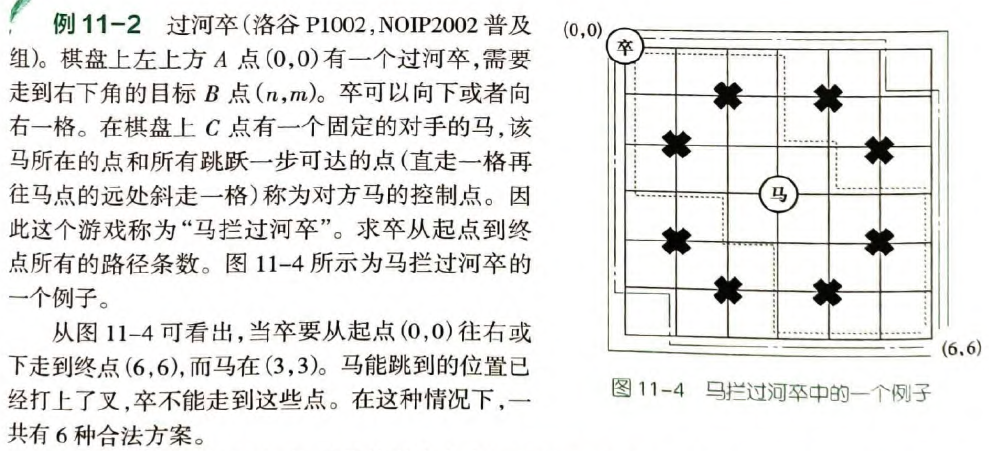
泛化问题:到达一般的点 (n, m) 的路径条数记为 a[n][m] ,则题设即求这个一般问题中令 (n, m) 为终点的情况。显然有
a[n][m] = a[n - 1][m] + a[n][m - 1] // 如果其中一者在边界, 只加一个
特殊值:
1. 对于马拦住的八个位置, a[x][y] = 0. 不妨记为-1便于判断.
2. a[0][0] = 1.
递推依次要判断的条件:
1. 两个子问题是否在棋盘内, 即 n - 1 >= 0, m - 1 >= 0, 不然只取一者
2. 两个子问题是否被马拦住, 即是否为 -1
3. 马拦住的位置是否在棋盘内
4. 因为我用-1标记, 假如最后结果是-1, 需要修改一下
我们可以检验几个点,比如 (1,0),(0,1),(1,1),(2,0)之类的验证上式。
#include <iostream>
#include <cstdio>
using namespace std;
const int MAXN = 30;
long long a[MAXN][MAXN];
const int dx[] = {0, -1, -2, -2, -1, 1, 2, 2, 1};
const int dy[] = {0, -2, -1, 1, 2, -2, -1, 1, 2};
int main() {
int n, m, x, y;
cin >> n >> m >> x >> y;
// 马, 注意马也引入了边界问题
for (int i = 0; i < 9; i++) {
int new_x = x + dx[i], new_y = y + dy[i];
if (0 <= new_x && new_x <= n && 0 <= new_y && new_y <= m) {
a[new_x][new_y] = -1;
}
}
// 边界
if (a[0][0] == -1 || a[n][m] == -1) {
cout << 0 << endl;
return 0;
}
a[0][0] = 1;
// 一行一行处理递推
for (int i = 0; i <= n; i++) {
for (int j = 0; j <= m; j++) {
if (i - 1 >= 0 && a[i][j] != -1 && a[i - 1][j] != -1) {
a[i][j] += a[i - 1][j];
}
if (j - 1 >= 0 && a[i][j] != -1 && a[i][j - 1] != -1) {
a[i][j] += a[i][j - 1];
}
// cout << a[i][j] << ' ';
}
// cout << endl;
}
cout << a[n][m] << endl;
return 0;
}

分析:
卡特兰数这个递推虽然很经典,但是看到一次还是会很震撼(
等会,如果抛去栈进出的动态画面,单纯观察序列(子问题)本身,好像有说法的。
入栈序列:[1, 2, 3]
对于出栈序列 [1, 2, 3] ,它最后出栈的元素是第3个元素 3 ,在它之前的 1, 2 可能有两种出栈方式,即考虑 h[3 - 1] 。
如果最后出栈的元素是第2个元素 2 ,则由于栈的性质,1一定在它之前出栈。
总而言之,子问题不仅包括某个元素入栈后的那些元素 h[n - k],还包括该元素入栈前的那些元素 h[k - 1] 。

ps. 递推还要顺手分析一下数值大小。(可以朴素地用求和式相减推一下通项。)
结论上,,这是指数级的,大约是 。
那么n=18对应 ,用 int 装结果就行。
#include <iostream>
#include <cstdio>
using namespace std;
int h[20] = {1, 1};
int main() {
int n;
cin >> n;
for (int i = 2; i <= n; i++) {
for (int j = 0; j < n; j++) {
h[i] += h[j] * h[i - 1 - j];
}
}
cout << h[n] << endl;
return 0;
}

思路容易乱,做一个整理:从没有子问题、到有子问题。
- 放松条件:不考虑递归,只有前面两个条件,则为 。例如 时,其本身计数为1,在它后面可以添加 三种情况,故计数为 。
- 添加条件:考虑递归。例如 时,之前是在 基础上添加了 三个计数;现在把 不看成每个问题计数为1(
result += 1),而是每个问题为需要调用函数计算的子问题(result += generate(i))。 - 在写好原始递归后,将其升级为备忘录。
(ps. 下述这个树的每个节点代表一次函数调用)
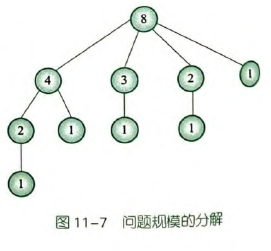
#include <iostream>
#include <cstdio>
using namespace std;
const int MAXN = 1010;
int a[MAXN] = {0};
// 原始递归, 再加个备忘录降一下TLE
void generate(int n) {
if (n == 1) {
a[1] = 1;
} else {
int result = 1; // [n]本身是一个
for (int i = 1; i <= n / 2; i++) {
if (a[i] == 0) generate(i); // 在它后面做n/2种选择
result += a[i];
}
a[n] = result;
}
}
int main() {
int n;
cin >> n;
generate(n);
cout << a[n] << endl;
return 0;
}
第二种思考方式是使用递推: f[i] = 1 + f[1] + f[2] + ... + f[i/2], f[1] = 1 。
#include <iostream>
#include <cstdio>
using namespace std;
const int MAXN = 1010;
int a[MAXN] = {0};
// 递推解法
void generate(int n) {
a[1] = 1;
for (int i = 2; i <= n; i++) { // 填充a[2]到a[n]
// f[i] = 1 + f[1] + f[2] + ... + f[i/2]
a[i] = 1;
for (int j = 1; j <= i/2; j++) a[i] += a[j];
}
}
int main() {
int n;
cin >> n;
generate(n);
cout << a[n] << endl;
return 0;
}

写递归时,一定记得写备忘录。
#include <iostream>
#include <cstdio>
using namespace std;
long long memo[21][21][21] = {0}; // 1~20
long long w(long long a, long long b, long long c) {
if (a <= 0 || b <= 0 || c <= 0) {
return 1;
} else if (a > 20 || b > 20 || c > 20) {
if (memo[20][20][20] == 0) memo[20][20][20]=w(20, 20, 20);
return memo[20][20][20];
} else if (a < b && b < c) {
if (memo[a][b][c-1] == 0) memo[a][b][c-1]=w(a,b,c-1);
if (memo[a][b-1][c-1] == 0) memo[a][b-1][c-1]=w(a,b-1,c-1);
if (memo[a][b-1][c] == 0) memo[a][b-1][c]=w(a,b-1,c);
return memo[a][b][c-1] + memo[a][b-1][c-1] - memo[a][b-1][c];
} else {
if (memo[a-1][b][c] == 0) memo[a-1][b][c]=w(a-1,b,c);
if (memo[a-1][b-1][c] == 0) memo[a-1][b-1][c]=w(a-1,b-1,c);
if (memo[a-1][b][c-1] == 0) memo[a-1][b][c-1]=w(a-1,b,c-1);
if (memo[a-1][b-1][c-1] == 0) memo[a-1][b-1][c-1]=w(a-1,b-1,c-1);
return memo[a-1][b][c]+memo[a-1][b-1][c]+memo[a-1][b][c-1]-memo[a-1][b-1][c-1];
}
}
int main() {
memo[0][0][0] = 1;
long long a, b, c;
while (1) {
cin >> a >> b >> c;
if (a == -1 && b == -1 && c == -1) {
break;
} else {
printf("w(%lld, %lld, %lld) = %lld\n", a, b, c, w(a, b, c));
}
}
return 0;
}

由简到繁思考。
- (不含递归)对于
[4CB],逐个字符读取。读到[时,读入这一段的数字,直到读到字母;然后读入字母,直到读到],将字母转成字母的重复。 - (包含递归)对于
[2[2CB]],读到[时,读入这一段的数字,直到读到[,则一直往后读,直到读到],对这一段调用函数,然后转成子问题结果的重复。
总而言之,我们的函数解释为将一段字符串展开。如果遇到递归,则对递归段调用函数,从而转化回将一段字符串展开的问题,然后再展开。
举个例子:
调用函数 expand("[2[2CB]]") 。
首先读入 [ 和数字 2 ,然后发现又有 [ ,需要先对后面一整段调用子函数,即 expand([2CB]]) ,调用后子函数将这一段展开为 CBCB] ,则字符串变为 [2CBCB] ,再同理展开即可。
#include <iostream>
#include <string>
using namespace std;
string expand() {
string s = "", X;
char c;
int D;
while (cin >> c) {
if (c == '[') {
cin >> D;
X = expand();
while (D--) s += X;
} else if (c == ']') {
return s;
} else {
s += c;
}
}
return s;
}
int main() {
cout << expand();
return 0;
}
贪心专题
背包问题用替换论证,调度类问题可能用交换论证。

贪心策略:按照 v[i] / m[i] 从高到低排序,然后拿入。
这个不是01背包(战略放弃可能得到更多),而是分数背包,贪心是最优的。
贪心证明:copy-and-paste。假设最优解某次在背包中放入了价值低的金币,则可以将这个金币替换为贪心的价值高的金币,价值不会降低。如是循环,直到最优解全部替换为贪心解,价值不会降低,所以贪心解为最优解。
#include <iostream>
#include <cstdio>
#include <algorithm>
using namespace std;
int n, T;
struct coin {
int m, v; // 总重量, 总价值
} coins[110];
bool cmp(coin a, coin b) {
// a.v / a.m > b.v / b.m
return a.v * b.m > a.m * b.v;
}
float greedy() {
int remain = T;
float res = 0; // 剩余空间, 已装价值
int i;
for (i = 0; i < n; i++) {
auto coin = coins[i];
if (coin.m > remain) break;
// 想不通就获取信息, 不要硬盯着代码看
//printf("remain: %d, coin.m: %d, coin.v: %d\n", remain, coin.m, coin.v);
res += coin.v;
remain -= coin.m;
}
// 允许分割
if (i < n) res += 1.0 * remain * coins[i].v / coins[i].m;
return res;
}
int main() {
cin >> n >> T;
for (int i = 0; i < n; i++) {
cin >> coins[i].m >> coins[i].v;
}
sort(coins, coins + n, cmp);
printf("%.2f\n", greedy());
return 0;
}

对于等待问题,画图出来会特别清晰。
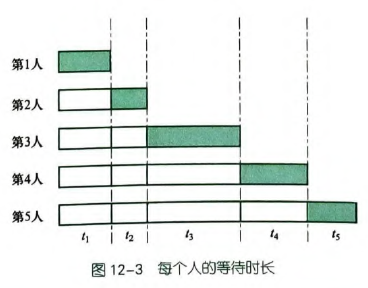
等待总时长$$s=(n-1)t_1+(n-2)t_2 + \dots + 1 \cdot t_{n-1} + 0 \cdot t_n$$贪心策略:前面的时间段系数大、后面的小。从而应当让接水时间较短的人先接。
贪心证明:调度类的问题使用交换论证。贪心得到的应该是接水时间的升序序列。反设最优解中有两者逆序( 但 ,则由前述可知系数 ),它们对等待总时长的贡献为 。将这两者交换后,贡献变为 。
后者减前者得到 ,即交换后贡献的等待时长更少,矛盾。
另外需要估算结果大小: , ,则最大情况下是 ,这铁定是不能用 int ()了。
#include <iostream>
#include <cstdio>
#include <algorithm>
using namespace std;
struct person {
int id, time;
} p[1010];
// 按照time, id升序
bool cmp(person a, person b) {
if (a.time != b.time) {
return a.time < b.time;
} else {
return a.id < b.id;
}
}
int main() {
int n;
cin >> n;
for (int i = 0; i < n; i++) {
p[i].id = i + 1;
cin >> p[i].time;
}
sort(p, p + n, cmp);
// 排队顺序
for (int i = 0; i < n; i++) {
cout << p[i].id << ' ';
}
cout << endl;
// 平均等待时间
long long total = 0;
for (int i = 0; i < n; i++) {
total += (n - 1 - i) * p[i].time;
}
printf("%.2f\n", 1.0 * total / n);
return 0;
}

结束时间越早,能够留给其他比赛的剩余时间越多。
贪心策略:按照结束时间降序排列,选取相容的所有活动。
#include <iostream>
#include <cstdio>
#include <algorithm>
using namespace std;
struct activity {
int s, e; // start, end
} a[1000010];
// 按照结束时间升序
bool cmp(activity a1, activity a2) {
return a1.e <= a2.e;
}
int main() {
int n, cnt = 0, cur_end = 0; // 活动总数, 结果, 当前结束时间
cin >> n;
for (int i = 0; i < n; i++) {
cin >> a[i].s >> a[i].e;
}
sort(a, a + n, cmp);
for (int i = 0; i < n; i++) {
if (a[i].s >= cur_end) { // 将活动a[i]选入
cur_end = a[i].e;
cnt++;
}
}
cout << cnt << endl;
return 0;
}

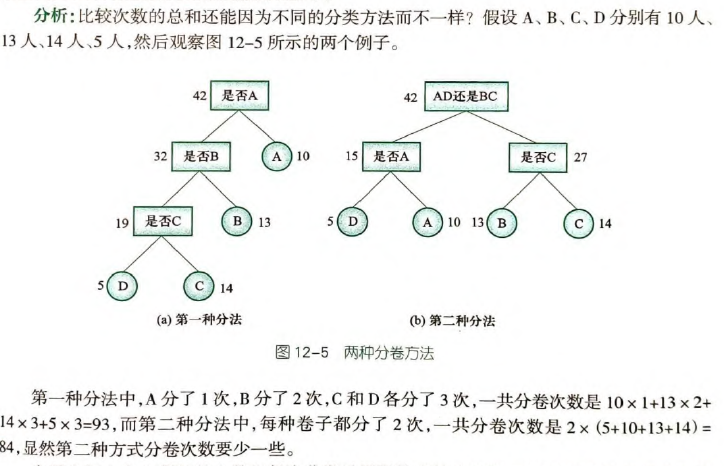
这里讲解哈夫曼树,即每次选取最小的两个节点,合并、放回,如是循环,直到全部完成合并。

语法:优先队列
priority_queue<int> pq; // 默认为大根堆less
priority_queue<int, vector<int>, greater<int>> pq; // 小根堆greater
#include <iostream>
#include <cstdio>
#include <queue>
using namespace std;
int main() {
priority_queue<int, vector<int>, greater<int>> pq;
int n, tmp, res = 0, a, b;
cin >> n;
for (int i = 0; i < n; i++) {
cin >> tmp;
pq.push(tmp);
}
while (pq.size() > 1) {
a = pq.top(); pq.pop();
b = pq.top(); pq.pop();
res += a + b;
pq.push(a + b);
}
cout << res << endl;
return 0;
}
还有一种方式是将原数组升序排序,然后新增一个队列。
每次比较数组头部的两个元素以取得最小值,合并结果始终置于队列中。
我们可以思考一下这样做的可行性:
(1) 初始
原数组升序,队列为空,
我们取的两个元素都在原数组中,将它们合并后加入队列。
(2) 递推
原数组已经升序排序。
而我们每次都取的是两个最小值进行合并,并将合并结果加入队列中,
意味着队列也是升序排序。
而数组和队列都是升序排序,又反过来保证我们每次取到的是最小值。
#include <iostream>
#include <cstdio>
#include <queue>
#include <algorithm>
#include <cstring>
using namespace std;
int n, n2, a1[10010], a2[10010], sum = 0;
int main() {
cin >> n;
memset(a1, 127, sizeof(a1)); // #include <cstring>
memset(a2, 127, sizeof(a2)); // 未存入初始化为大数, 便于比较
for (int i = 0; i < n; i++) cin >> a1[i];
sort(a1, a1 + n);
int i = 0, j = 0, w;
for (int k = 1; k < n; k++) { // 合并n-1次
w = a1[i] < a2[j] ? a1[i++] : a2[j++];
w += a1[i] < a2[j] ? a1[i++] : a2[j++];
sum += w;
a2[n2++] = w; // 加入第二个队列
}
cout << sum;
return 0;
}
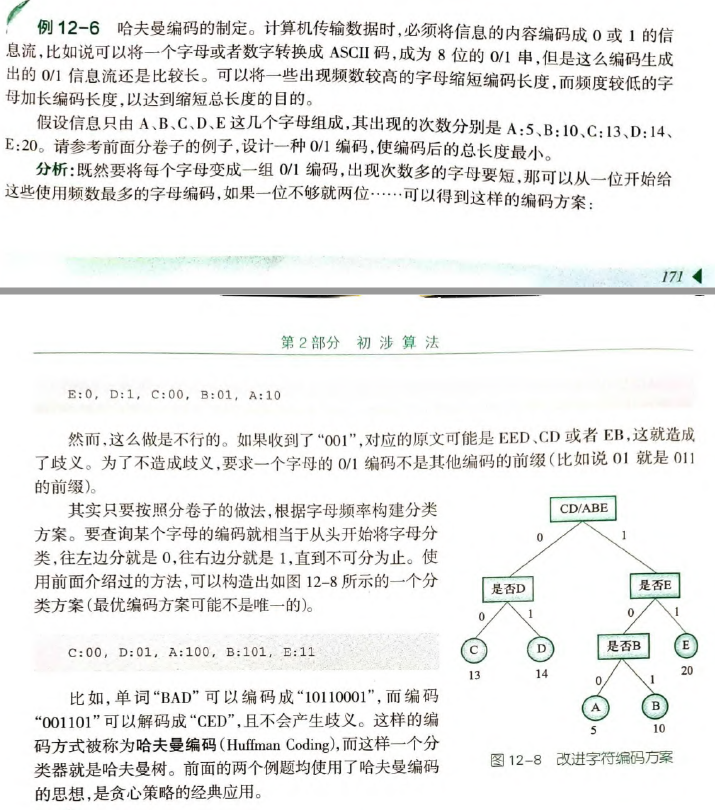
二分查找与二分答案专题
二分的本质是一段满足某条件、另一段不满足。
往往要找到满足或不满足的端点。
二分是在遍历上的优化,能够使用二分的问题一定可以暴力遍历,以找到是否满足某条件的端点。
由于各种 +1 -1 那种写法对我来说有点复杂,
我这里采取:
闭区间二分查找(例13-3)。以下以升序为例。
- 如果要找等于某个数的从前往后第一个数字,转化为找满足“大于等于该数”性质的第一个数字,满足条件的部分内利用
r = mid - 1逼近端点。- 如果要找等于某个数的从前往后最后一个数字,转化为找满足“小于等于该数”性质的最后一个数字,满足条件的部分内利用
l = mid + 1逼近端点。

#include <iostream>
#include <cstdio>
using namespace std;
int a[1000010], n, m;
int bsearch(int x) {
int l = 1, r = n, ans, mid;
while (l <= r) {
mid = l + (r - l) / 2;
if (a[mid] >= x) { // 找到满足>=的第一个端点
ans = mid;
r = mid - 1; // 因为是找第一个, 所以这里是r
} else {
l = mid + 1;
}
}
if (a[ans] == x) return ans;
else return -1;
}
int main() {
cin >> n >> m;
for (int i = 1; i <= n; i++) { // 题目要求输出序号而非下标
scanf("%d", &a[i]);
}
// 只是二分查找, 数据量比较大, 不需要sort
int request;
for (int i = 0; i < m; i++) {
scanf("%d", &request);
printf("%d ", bsearch(request));
}
printf("\n");
return 0;
}

对于每个数B,A=B+C是一段连续的区间。
例如:找到所有A=B+C的个数,假设C=4。当我们遍历到元素B=3时,B和C都是确定的,所以A=B+C也是一个确定值(7=4+3),这个确定值一定是连续出现的一整段(如图中下标6~7)。
因此,对于每个数B,问题转化成了统计B+C的出现次数,即找到相同值连续段的左右端点。
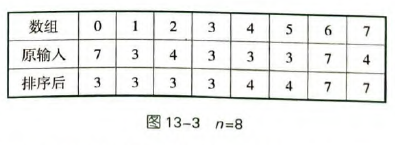
统计有序数列中某个数的出现次数,一种方法是利用二分查找、找到左端点和右端点。这是 的。
这里介绍 lower_bound 和 upper_bound :
[Begin, end) 左闭右开.
lower_bound(begin, end, val); // 找到出现的第一个位置, 返回地址
upper_bound(begin, end, val); // 找到出现的最后一个位置(的后面), 返回地址
统计个数可以写为:
upper_bound(begin, end, val) - lower_bound(begin, end, val)
ps. lower_bound(a, a+n, val + 1)等价于upper_bound(a, a+n, val).
#include <iostream>
#include <cstdio>
#include <algorithm>
using namespace std;
int a[200010], n, c;
long long res = 0;
int main() {
scanf("%d%d", &n, &c);
for (int i = 0; i < n; i++) {
scanf("%d", &a[i]);
}
sort(a, a + n);
// 对于每个数B, 给定C, 统计A=B+C的出现次数
for (int i = 0; i < n; i++) {
res += upper_bound(a, a + n, a[i] + c) - lower_bound(a, a + n, a[i] + c);
}
printf("%lld\n", res);
return 0;
}
另一种 的思路是,我们可以维护双指针手动实现类似lower_bound和upper_bound的效果:随着我们要查询的 a[i] + c 逐渐增大,它所在的段也逐渐右移。因此我们可以维护双指针指向它的左右端点,始终右移。
两个指针移动的距离不超过 n ,所以是 的。
#include <iostream>
#include <cstdio>
#include <algorithm>
using namespace std;
int a[200010], n, c;
long long res = 0;
int main() {
scanf("%d%d", &n, &c);
for (int i = 0; i < n; i++) {
scanf("%d", &a[i]);
}
sort(a, a + n);
// 对于每个数B, 给定C, 统计A=B+C的出现次数
int l = 0, r = 0;
for (int i = 0; i < n; i++) {
// 记住! 数组访问一定要处理下标问题
while (l < n && a[l] < a[i] + c) l++; // lower_bound
while (r < n && a[r] <= a[i] + c) r++; // upper_bound
res += r - l;
}
printf("%lld", res);
return 0;
}
“具有单调性判定”的问题:
例如升序数组 [l, r),条件是大于等于 。
当 a[mid] 满足条件时,查找范围是 [l, mid] 或者 [l, mid + 1) ;
当 a[mid] 不满足条件时,查找范围是 [mid + 1, r) 。

很巧妙:我们找到了单调性。二分查找一定是朴素查找的优化。
朴素查找:从低往高依次遍历高度 ,收集到的木材数量单调递减。 取得最大的 使得条件成立,且此时 不成立。
二分查找:设定条件为 “当砍树高度为 时,可以获取数量大于等于 的木材” ,
以上述题目为例、 时条件满足,大于时不满足。
二分模板说明:
这里的二分是定义在闭区间[l, r]上的,
[l, x]满足某性质(例中的val >= m),
如果要找满足该性质的最大端点,则在满足条件的部分内写ans = mid; l = mid + 1;,另一边写r = mid - 1,即利用l继续逼近。
如果要找满足该性质的最小端点,则在满足条件的部分内写ans = mid; r = mid - 1;,另一边写l = mid + 1,即利用r继续逼近。
#include <iostream>
#include <cstdio>
using namespace std;
int a[1000010], n;
long long wood(int x) { // 树高x收集到的木材数
long long sum = 0;
for (int i = 0; i < n; i++) {
if (a[i] > x) sum += a[i] - x;
}
return sum;
}
int bsearch(long long m) { // 找到树高
// 收集到的木材随树高具有单调性
int l = 0, r = 4e5, ans = 0, mid;
while (l <= r) {
mid = l + (r - l) / 2;
long long val = wood(mid);
if (val >= m) {
// 要找满足条件的最大端点
ans = mid;
l = mid + 1; // 往最大端点逼近
} else {
r = mid - 1;
}
}
return ans;
}
int main() {
long long m;
cin >> n >> m;
for (int i = 0; i < n; i++) {
scanf("%d", &a[i]);
}
printf("%d", bsearch(m));
return 0;
}

这个也能二分?我觉得二分题目就是题面上一眼完全看不出来,
二分条件:单调性是随着距离增大,是否能够安置。可见,距离较小时这个条件满足,距离超过某个阈值后一定不满足。
贪心:从最左端开始,每隔大于等于 的距离,能安置就安置。
贪心证明:copy-and-paste。从前往后遍历最优解序列,找到第一个不满足贪心给出的位置的牛,将它替换为贪心给出的位置(更靠前),则该牛剩余的距离不减少,且不影响其余牛的安置。如是反复。
#include <iostream>
#include <cstdio>
#include <algorithm>
using namespace std;
int a[1000010], n, c;
bool greedy(int x) { // 验证当前距离是否可以安置所有的牛
int i;
int cnt = 1; // 第一个隔间i = 0默认安置, 往它后面计算距离
int next_min = a[i] + x; // 下一个隔间至少的坐标
for (i = 1; i < n && cnt < c; i++) {
if (a[i] >= next_min) {
next_min = a[i] + x; // 以当前隔间为基准计算
cnt++;
}
}
return cnt == c;
}
int bsearch(int l, int r) {
int mid, ans;
while (l <= r) {
mid = l + (r - l) / 2;
if (greedy(mid)) { // 要找"可以安置"的最大距离
ans = mid;
l = mid + 1;
} else {
r = mid - 1;
}
}
return ans;
}
int main() {
scanf("%d%d", &n, &c);
for (int i = 0; i < n; i++) {
scanf("%d", &a[i]);
}
sort(a, a + n);
printf("%d\n", bsearch(0, 1e9));
return 0;
}

如果没有什么数学性质,我会想到比较暴力的在200个区间内每个都二分一下。
补兑,答案就是这么做的。
但是毕竟我们还是知道一元三次方程长什么样,比如↗↘↗。它是有三段单调的。
因此,可以考虑首先找到一个根(局部单调所以我觉得应该可以收敛?),然后在它的两侧探索,然后再根据已经找到的两个根、再在三段内探索,总共需要对六段区间执行二分,比上面200个还是好点。
根据零点存在性定理,如果中点和某端点正负相同,则零点一定在中点的另一侧。
#include <iostream>
#include <cstdio>
#include <cmath>
using namespace std;
#define eps 1e-4
double a, b, c, d;
double f(double x) {
return a * x * x * x + b * x * x + c * x + d;
}
void bsearch() { // 区间 [l, r) 上的根
for (int i = -100; i <= 100; i++) {
double l = i, r = i + 1, mid;
if (fabs(f(l)) < eps) {
printf("%.2lf ", l);
} else if (fabs(f(r)) < eps) { // 左闭右开, 不管
continue;
} else if (f(l) * f(r) < 0) { // 有根
while (r - l > eps) {
mid = (l + r) / 2;
if (f(l) * f(mid) >= 0) { // 正负相同, 在另一侧
l = mid;
} else {
r = mid;
}
}
printf("%.2lf ", l);
}
}
}
int main() {
cin >> a >> b >> c >> d;
bsearch();
return 0;
}
搜索专题
深度优先:优先考虑搜索的深度,到头了再进行处理。


下述其实是回溯板子、坐标占位判断、坐标映射三部分内容的结合体。
- 回溯板子,满足条件时打印、枚举可行选择、保存并调用后取消(注意取消一切影响,包括原始数组、行列是否有数字的数组等)。
- 坐标占位判断是通过三个数组实现的,每个元素
b[x][y]代表“第x行/列/块是否有数字y”,所以x和y的取值范围都是1~4。 - 坐标映射很像PyTorch的Tensor。函数参数使用的坐标是116,为了把它映射到行号和列号,需要先映射到015,然后使用整除
/和取模%(本质是移位和位与)。而块号可以由行号和列号映射得到。当然也可以直接用原始坐标求得,见下。
这里提供一个位运算直接求得块号的过程,仅限1~16。
def map_number(n):
'''将n: 1~16映射到00110011 22332233.'''
idx = n - 1
# 高2位决定基本值: 00->0, 01->0, 10->2, 11->2
high_bits = (idx >> 2) & 0b10
# 低2位决定是否+1: 00->0, 01->0, 10->1, 11->1
low_bits = (idx & 0b10) >> 1
return high_bits + low_bits
// 书上没提这道题的来源, 我按照洛谷T581492微调了一下代码
// 现在只打印字典序最小的一个例子, 并且打印出答案288
#include <iostream>
#include <cstdio>
using namespace std;
#define size 5
int a[size][size], n = 4 * 4, ans = 0;
int b1[size][5], b2[size][5], b3[size][5]; // 横行, 竖列, 四小块
// b1[row][i]: 第row行是否有数字i
int printed = 0;
void dfs(int x) { // 从左上到右下依次记为第1~16个格子
if (x > n) { // 填满时, 合法, 记录答案
ans++;
if (!printed) {
for (int i = 1; i <= 4; i++) {
for (int j = 1; j <= 4; j++) {
printf("%d ", a[i][j]);
}
printf("\n");
}
//printf("\n");
printed = 1;
}
return;
}
// 序号变换到 0~15 → 映射到行列从0开始的4*4二维数组 → 变换到行列从1开始
int row = (x - 1) / 4 + 1; // 横行号, 1~4位于第一行
int col = (x - 1) % 4 + 1; // 竖列号, 1~4位于列1~4
// 行列变换回从0开始 → 步长为2的"2*2"二维数组映射到一维 → 从1开始
int block = (row - 1) / 2 * 2 + (col - 1) / 2 + 1; // 四小块号
// 枚举这个空能填的数字1~4
for (int i = 1; i <= 4; i++) {
if (b1[row][i] == 0 && b2[col][i] == 0 && b3[block][i] == 0) {
a[row][col] = i;
b1[row][i] = 1; b2[col][i] = 1; b3[block][i] = 1;
dfs(x + 1);
b1[row][i] = 0; b2[col][i] = 0; b3[block][i] = 0;
a[row][col] = 0;
}
}
}
int main() {
dfs(1);
printf("%d\n", ans);
return 0;
}

按行搜索,因为每一行只能放一个。
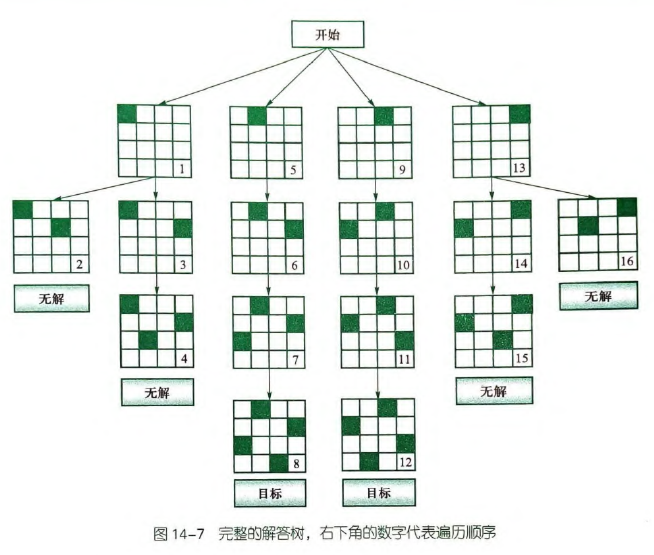
#include <iostream>
#include <cstdio>
using namespace std;
int a[14][14], ans = 0, n;
int b1[14], b2[14], b3[30], b4[30];
// 第n行, 第n列, 第n右上-左下斜线, 第n左上-右下斜线是否有皇后
int count = 3; // 输出前三种放法
void dfs(int row) {
// 回溯三步走: 结果、遍历、撤销
if (row > n) { // 放置完毕
ans++;
if (count > 0) {
for (int i = 1; i <= n; i++) {
for (int j = 1; j <= n; j++) {
if (a[i][j] == 1) printf("%d ", j);
}
}
printf("\n");
count--;
}
return;
}
for (int col = 1; col <= n; col++) {
// 例如1行1列, diag3=1; 2行1列或1行2列, diag3=2; 3行1列或2行2列或1行3列, diag3=3
int diag3 = row + col - 1;
// n行1列, diag4=1; n-1行1列或n行2列, diag4=2; ...
int diag4 = n - row + col;
if (b1[row] == 0 && b2[col] == 0 && b3[diag3] == 0 && b4[diag4] == 0) {
a[row][col] = 1;
b1[row] = 1; b2[col] = 1; b3[diag3] = 1; b4[diag4] = 1;
dfs(row + 1);
b1[row] = 0; b2[col] = 0; b3[diag3] = 0; b4[diag4] = 0;
a[row][col] = 0;
}
}
}
int main() {
scanf("%d", &n);
dfs(1);
printf("%d", ans);
return 0;
}

枚举子集问题可以使用搜索回溯来解决,但是需要枚举的元素较多时仍然比较慢。可以使用背包问题模型来高效解决本问题。
仅考虑一个科目的情况。
对于每个科目,需要尽可能均分为两堆:取子集,总耗时不超过一半且尽可能地大。
拆分一下知识点:
- 把一个集合划分为尽可能均等的两个子集。这是通过逐渐加入元素,直到不超过大小的一半实现的。
- 如果满足条件,则选择题目和不选择题目都要处理。否则只处理不选择题目。
- 当两个时间并行时,它们重叠了,时间总数的贡献量应该取更大的那个时间(
max(maxtime, sum - maxtime) = sum - maxtime, if maxtime <= sum / 2)。
#include <iostream>
#include <cstdio>
using namespace std;
int a[21]; // s[i] <= 20, 每一科不超过20道
int maxtime, curtime, sum, ans = 0, n;
void dfs(int x) { // 从第0道到第s[i] - 1道
if (x >= n) { // 0~n-1题目计算curtime已处理完毕
maxtime = max(maxtime, curtime);
return;
}
// 确定当前下标x的题目是否加入子集
if (curtime + a[x] <= sum / 2) {
curtime += a[x];
dfs(x + 1);
curtime -= a[x];
}
// 注意下面这里不能写进else:
// 如果满足条件, 则选择该题目和"不选择该题目"都要处理.
// 如果不满足条件, 则只处理"不选择该题目".
dfs(x + 1);
}
int main() {
int s[4];
cin >> s[0] >> s[1] >> s[2] >> s[3];
// 首先输入并统计当前科目这些题目的总时长, 一会要当一半的条件
for (int i = 0; i < 4; i++) {
n = s[i];
sum = 0, maxtime = 0, curtime = 0;
for (int j = 0; j < n; j++) {
cin >> a[j];
sum += a[j];
}
dfs(0);
// 两个作业并行, 而maxtime <= sum / 2,
// 因此sum - maxtime一定不小于maxtime,
// 所以这里应该加更长的那个时间
ans += sum - maxtime;
}
cout << ans << endl;
return 0;
}
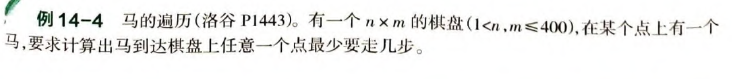
既然是任意一个点,就是要把所有情况都给遍历出来,相当于建立一个广度遍历树。
注意:在向周围扩散时,顺便跟坐标队列一起记录下距离。
#include <iostream>
#include <cstdio>
#include <queue>
using namespace std;
int a[410][410], n, m;
bool visited[410][410];
const int dx[] = {-1, -2, -2, -1, 1, 2, 2, 1};
const int dy[] = {-2, -1, 1, 2, -2, -1, 1, 2};
queue<int> qx;
queue<int> qy;
queue<int> qdist;
void bfs(int original_x, int original_y) {
int dist = 0;
// 1. 初始位置入队
a[original_x][original_y] = dist;
visited[original_x][original_y] = true;
qx.push(original_x);
qy.push(original_y);
qdist.push(dist + 1);
// 2. 按队列顺序处理
int x, y;
while (!qx.empty()) { // qy和qx大小相同
x = qx.front(); qx.pop();
y = qy.front(); qy.pop();
dist = qdist.front(); qdist.pop();
// 给8个邻居标距离, 然后距离++
for (int i = 0; i < 8; i++) {
int new_x = x + dx[i], new_y = y + dy[i];
if (new_x >= 1 && new_x <= n && new_y >= 1 && new_y <= m && !visited[new_x][new_y]) {
visited[new_x][new_y] = true;
a[new_x][new_y] = dist;
qx.push(new_x);
qy.push(new_y);
qdist.push(dist + 1);
}
}
}
}
int main() {
cin >> n >> m;
int x, y;
cin >> x >> y;
bfs(x, y);
for (int i = 1; i <= n; i++) {
for (int j = 1; j <= m; j++) {
if (!visited[i][j]) printf("-1 ");
else printf("%d ", a[i][j]);
}
printf("\n");
}
return 0;
}

感觉bfs你去真的想电梯/马的周游的过程就想复杂了,不如就从深度广度遍历一棵选择树的角度去想。像这道题就是二叉树带剪枝,很明确。
#include <iostream>
#include <cstdio>
#include <queue>
using namespace std;
int n, a[210];
bool visited[210];
struct node {
int floor, d; // 队列中记录的层数和按钮次数
};
int bfs(int A, int B) {
queue<node> q;
node x;
q.push((node){A, 0});
visited[A] = true;
while (!q.empty()) {
x = q.front(); q.pop();
if (x.floor == B) break;
for (int sign = -1; sign <= 1; sign += 2) {
// 枚举向上和向下两种选择
int new_x = x.floor + sign * a[x.floor];
if (1 <= new_x && new_x <= n && !visited[new_x]) {
q.push((node){new_x, x.d + 1});
visited[new_x] = true;
}
}
}
if (x.floor == B) return x.d;
else return -1;
}
int main() {
int A, B;
cin >> n >> A >> B;
for (int i = 1; i <= n; i++) {
cin >> a[i];
}
printf("%d", bfs(A, B));
return 0;
}

相当于知道每个格子被烧焦的时间。
剪枝条件:如果目标格子的最早到达时间比被烧焦时间晚,则不能扩展。
区别于前述的剪枝条件:已访问(visited)。
ps. 最后一个用例有问题,有坐标大于300的情况,所以for循环至少开到305。
#include <iostream>
#include <cstdio>
#include <queue>
#include <cstring>
using namespace std;
int a[310][310], ans[310][310]; // 被烧时间, 最早到达时间
struct node {
int x, y;
};
const int dx[] = {0, -1, 0, 0, 1};
const int dy[] = {0, 0, -1, 1, 0};
void bfs() { // 奶牛初始位于(1, 1)
queue<node> q;
node now;
q.push((node){1, 1});
ans[1][1] = 0;
while (!q.empty()) {
now = q.front(); q.pop();
for (int k = 1; k <= 4; k++) { // 奶牛向四个方向移动
int x = now.x + dx[k], y = now.y + dy[k];
int new_t = ans[now.x][now.y] + 1;
if (x >= 1 && y >= 1 && ans[x][y] == -1 && new_t < a[x][y]) { // 允许写入ans[x][y], 且待更新的到达时间小于被烧时间 (否则已经被烧了)
ans[x][y] = new_t;
q.push((node){x, y});
}
}
}
int result = 2147483647;
// 用例有问题, 这里不能写300
for (int i = 1; i <= 305; i++) {
for (int j = 1; j <= 305; j++) {
if (ans[i][j] != -1 && a[i][j] > 1000) {
// 待在这里以后不会被烧
result = min(result, ans[i][j]);
}
}
}
if (result == 2147483647) {
printf("-1\n");
} else {
printf("%d\n", result);
}
}
int main() {
memset(ans, -1, sizeof(ans)); // -1
memset(a, 0x7f, sizeof(a)); // 很大的数
int M, x, y, t;
scanf("%d", &M);
for (int i = 0; i < M; i++) {
scanf("%d%d%d", &x, &y, &t);
x += 1; y += 1; // 转成1~301, 便于边界处理
for (int j = 0; j < 5; j++) { // 烧五个格子, 取最早
if ((x + dx[j] >= 1) && (y + dy[j] >= 1)) {
a[x + dx[j]][y + dy[j]] = min(t, a[x + dx[j]][y + dy[j]]);
}
}
}
bfs();
return 0;
}
基础数据结构
字符串专题
知识
memset的头文件为cstring。

字符串的头文件为string。

7. find的返回值备注:s.find(str [,pos])在没找到时会返回string::npos, 需要强转为int才是-1, 否则直接输出得到 size_t 的最大值,可能是一个大数.

举例
以下三道题目利用字符串的七大常用方法,实现了字符计数、字符串处理和单词统计(空格法查找单词,给源文档和待查字符串前后都添加空格)。

#include <iostream>
#include <string>
using namespace std;
int main() {
string s;
long long ans = 0;
while (cin >> s) {
ans += s.size();
}
cout << ans << endl;
return 0;
}

// 分析:
// 1. 分派指令.
// 2. 对于每个指令, 使用字符串常用的四个方法实现.
// 坑: s.find(str [,pos])在没找到时会返回string::npos, 需要强转为int才是-1.
#include <iostream>
#include <cstdio>
#include <string>
using namespace std;
void sappend(string& document, string s) {
document += s;
cout << document << endl;
}
void struncate(string& document, int a, int b) {
document = document.substr(a, b);
cout << document << endl;
}
void sinsert(string& document, int a, string s) {
document = document.insert(a, s);
cout << document << endl;
}
void sfind(string document, string s) {
cout << document.find(s) << endl;
}
int main() { // 命令行分派, 输出均由相应代码处理
int n;
cin >> n;
string document;
cin >> document;
int opt;
while (n--) {
cin >> opt;
if (opt == 1) {
string s;
cin >> s;
sappend(document, s);
} else if (opt == 2) {
int a, b;
cin >> a >> b;
struncate(document, a, b);
} else if (opt == 3) {
int a;
string s;
cin >> a >> s;
sinsert(document, a, s);
} else if (opt == 4) {
string s;
cin >> s;
sfind(document, s);
}
}
return 0;
}

// 1. 读入但不区分大小写.
// 2. 为了统计出现次数和第一次出现的位置, 可以使用 s.find(str, pos), 从pos开始查找.
// 3. (重要: 空格法查找"单词") 可以给单词前后加空格' ', 以防止在单词内查找.
#include <iostream>
#include <cstdio>
#include <string>
using namespace std;
int main() {
// 读入并不区别大小写
string word, s;
getline(cin, word);
getline(cin, s);
for (int i = 0; i < word.size(); i++) {
if ('A' <= word[i] && word[i] <= 'Z') {
word[i] += 'a' - 'A';
}
}
for (int i = 0; i < s.size(); i++) {
if ('A' <= s[i] && s[i] <= 'Z') {
s[i] += 'a' - 'A';
}
}
// 为了查找"单词", 通过空格法
word = ' ' + word + ' ';
s = ' ' + s + ' ';
int cnt = 0, firstpos = 0;
// 输出第一个位置
firstpos = s.find(word);
if (firstpos == -1) {
// 不存在, 只输出-1
cout << -1 << endl;
} else {
int pos = firstpos;
while (pos != -1) {
cnt++;
pos = s.find(word, pos + 1); // 从pos + 1开始找下一个
}
// 输出出现次数和第一次出现的位置
cout << cnt << ' ' << firstpos << endl;
}
return 0;
}
结构体专题
知识
举例

#include <iostream>
#include <cstdio>
#include <string>
using namespace std;
struct student {
string name;
int chinese, math, english;
} a, ans;
// 注意只需要最厉害的一个学生, 因此只需要当前结构体和最好结构体即可, 不需要存储所有学生
// 关于90pts: 以下是通过>来更新ans的.
// 默认的ans是{"", 0, 0, 0}, 如果用例中有{"name", 0, 0, 0}的情况, 不特判的代码会少更新一步.
int main() {
int n;
cin >> n;
for (int i = 0; i < n; i++) {
cin >> a.name >> a.chinese >> a.math >> a.english;
if (i == 0) ans = a; // 加这一行, 90pts -> 100pts
if (a.chinese + a.math + a.english > ans.chinese + ans.math + ans.english) {
ans = a;
}
}
cout << ans.name << ' ' << ans.chinese << ' ' << ans.math << ' ' << ans.english << endl;
return 0;
}

// 因为是操练结构体, 直接遍历即可(O(n^2)).
// 当然, 先排序再遍历会更快(O(nlogn)).
#include <iostream>
#include <cstdio>
#include <string>
#define MAXN 1010
using namespace std;
struct student {
string name;
int chinese, math, english;
} a[MAXN];
bool check(int x, int y, int z) { // |x - y| <= z
return abs(x - y) <= z;
}
int main() {
int n;
cin >> n;
for (int i = 0; i < n; i++) {
cin >> a[i].name >> a[i].chinese >> a[i].math >> a[i].english;
}
for (int i = 0; i < n; i++) {
for (int j = i + 1; j < n; j++) {
if (check(a[i].chinese, a[j].chinese, 5) &&
check(a[i].math, a[j].math, 5) &&
check(a[i].english, a[j].english, 5) &&
check(a[i].chinese + a[i].math + a[i].english, a[j].chinese + a[j].math + a[j].english, 10)
) {
cout << a[i].name << ' ' << a[j].name << endl;
}
}
}
return 0;
}

关于结构体的构造函数:在写构造函数时,不需要写 struct 。
使用时,按照传参的形式。因为是在函数内部,所以定义了一个局部变量。
#include <iostream>
#include <cstdio>
using namespace std;
struct student {
int id, course_grade, extend_grade;
double score;
student(int _id, int _course_grade, int _extend_grade) {
// 下述的this->可以省略
this->id = _id;
this->course_grade = _course_grade;
this->extend_grade = _extend_grade;
this->score = 0.7 * _course_grade + 0.3 * _extend_grade;
}
int sum() {
return course_grade + extend_grade;
}
};
bool is_excellent(student s) {
return (s.score >= 80) && (s.sum() > 140);
}
int main() {
int n;
cin >> n;
for (int i = 0; i < n; i++) {
int tmp_id, tmp_cg, tmp_eg;
cin >> tmp_id >> tmp_cg >> tmp_eg;
student s(tmp_id, tmp_cg, tmp_eg); // 构造临时变量
if (is_excellent(s)) {
cout << "Excellent" << endl;
} else {
cout << "Not excellent" << endl;
}
}
return 0;
}
线性表专题
知识
本节包括栈、队列和链表。


stack在追求极致运行速度时,需要打开-O2优化。否则需要自己手写栈。



举例

主要是介绍一下vector,作为数组的替代。
#include <iostream>
#include <cstdio>
#include <vector>
using namespace std;
int main() {
int n, m, tmp;
cin >> n >> m;
vector<int> v;
for (int i = 0; i < n; i++) {
scanf("%d", &tmp);
v.push_back(tmp);
}
for (int i = 0; i < m; i++) {
scanf("%d", &tmp);
printf("%d\n", v[tmp - 1]);
}
return 0;
}

坑:变量名最好别叫 i, j, k ,不然你写个 for 循环铁定出问题。
#include <iostream>
#include <cstdio>
#include <vector>
using namespace std;
int main() {
int n, q, opt, i, j, k; // 其实一般别把变量名设成i, j, k比较好
cin >> n >> q;
vector<vector<int>> v(n + 10);
while (q--) {
scanf("%d", &opt);
if (opt == 1) {
scanf("%d%d%d", &i, &j, &k);
if (v[i].size() <= j) {
v[i].resize(j + 10);
}
v[i][j] = k;
} else if (opt == 2) {
scanf("%d%d", &i, &j);
cout << v[i][j] << endl;
}
}
return 0;
}


以下是按Uva673原题写的,只有小括号和中括号,没有大括号。
#include <iostream>
#include <cstdio>
#include <stack>
#include <string>
using namespace std;
int main() {
stack<char> stk;
int n;
cin >> n;
string tmp;
while (n--) {
cin >> tmp;
int i, n = tmp.size();
for (i = 0; i < n; i++) {
char c = tmp[i];
if (c == '[' || c == '(') {
stk.push(c);
} else if (c == ']') {
if (stk.empty() || stk.top() != '[') {
break;
} else {
stk.pop();
}
} else if (c == ')') {
if (stk.empty() || stk.top() != '(') {
break;
} else {
stk.pop();
}
}
}
if (!stk.empty() || i != tmp.size()) {
printf("No\n");
} else {
printf("Yes\n");
}
while (!stk.empty()) stk.pop();
}
return 0;
}

“越早写下的括号,离可能产生匹配的地方越远,越晚得到匹配。先进后出。”
#include <iostream>
#include <cstdio>
#include <stack>
using namespace std;
int main() {
stack<int> stk;
char ch;
int num = 0, x, y;
do {
ch = getchar();
if ('0' <= ch && ch <= '9') {
num = 10 * num + (ch - '0');
} else if (ch == '.') {
stk.push(num);
num = 0;
} else if (ch != '@') {
x = stk.top(); stk.pop();
y = stk.top(); stk.pop();
if (ch == '+') stk.push(y + x);
else if (ch == '-') stk.push(y - x);
else if (ch == '*') stk.push(y * x);
else if (ch == '/') stk.push(y / x);
}
} while (ch != '@');
printf("%d\n", stk.top());
return 0;
}


#include <iostream>
#include <cstdio>
#include <queue>
using namespace std;
int n, k, x;
queue<int> q;
int main() {
cin >> n >> k;
for (int i = 1; i <= n; i++) {
q.push(i);
}
// 这里是P1996, 要n个人的顺序
while (!q.empty()) { // 如果要n-1个人的, 这里改为 q.size() > 1
for (int i = 1; i <= k; i++) {
x = q.front(); q.pop();
if (i != k) {
q.push(x);
} else {
printf("%d ", x);
}
}
}
return 0;
}
链表是这样的一个遍历接口:
即用一个初始变量 i 和一个指向每个元素下一个的数组 Next 即可组织链表。
for (int i = 1; i != 0; i = Next[i])
printf("%d ", i);

// 注意, pre, nxt和tot都是"指针", 只有key是值
// 这写法还挺好
// 本写法不包括index数组, 所以每次由值找到指针是O(n)的, 优化见下一题
struct node {
int pre, nxt;
int key;
node (int _k = 0, int _p = 0, int _n = 0) {
pre = _p; nxt = _n; key = _k;
}
}
node s[1005]; // 由序号到节点
int tot = 0; // total, 已使用的位置数量, 下一个可用的是 s[tot + 1]
// 链表起点是s[1]
int find(int x) {
int now = 1;
while (now && s[now].key != x) now = s[now].nxt;
}
// 把y插在x后面.
// 相当于: 根据值找到x的位置, 分配y (位置为++tot), 后插y
void ins_back(int x, int y) {
int now = find(x);
s[++tot] = node(y, now, s[now].nxt);
s[s[now].nxt].pre = tot;
s[now].nxt = tot;
}
// 把y插在x前面.
void ins_front(int x, int y) {
int now = find(x);
s[++tot] = node(y, s[now].pre, now);
s[s[now].pre].nxt = tot;
s[now].pre = tot;
}
// 值为x的节点的下一个节点的值为多少
int ask_back(int x) {
int now = find(x);
return s[s[now].nxt].key;
}
int ask_front(int x) {
int now = find(x);
return s[s[now].pre].key;
}
// ps. 似乎并不考虑回收空间,
// 不然我感觉可以跟tot交换一下, 然后再tot--.
void del(int x) {
int now = find(x);
int pre = s[now].pre, nxt = s[now].nxt;
s[pre].nxt = nxt;
s[nxt].pre = pre;
}
以上是一个使用数组而非指针实现的双向链表。最好把 find 换成一个数组或者 unordered_map ,这样的话根据某个元素值找到它的节点就是 的。不然每次都要 遍历。

前后插、维护index数组都很平常,
但是易错的是初始化。注意要初始化置空的前提是存在无参的构造函数。
#include <iostream>
#include <cstdio>
using namespace std;
int index[100010] = {0};
int tot = 0;
struct node {
int val, pre, nxt;
node(int _v = 0, int _p = 0, int _n = 0) {
val = _v;
pre = _p;
nxt = _n;
}
}s[100010];
// 注意这里要初始化一个数组的话必须保证有空参数构造函数
// 在值为x的右边插入值为y
void ins_back(int x, int y) {
int now = index[x];
// 值, 指针, 指针
s[++tot] = node(y, now, s[now].nxt);
s[s[now].nxt].pre = tot; // 注意这两行的先后
s[now].nxt = tot;
index[y] = tot;
}
void ins_front(int x, int y) {
int now = index[x];
// 值, 指针, 指针
s[++tot] = node(y, s[now].pre, now);
s[s[now].pre].nxt = tot;
s[now].pre = tot;
index[y] = tot;
}
void del(int x) {
int now = index[x];
int pre = s[now].pre, nxt = s[now].nxt;
s[pre].nxt = nxt;
s[nxt].pre = pre;
index[x] = 0;
}
int main() {
// 先初始化, 然后插入, 删除, 打印
// s[0] = node();
// index[0] = 0; // 初始化时已置
// 按照要求, 插入第一个同学
ins_back(0, 1);
int n, k, p, m, x;
cin >> n;
for (int i = 2; i <= n; i++) {
cin >> k >> p;
// 插到k号同学的右边/左边
p ? ins_back(k, i) : ins_front(k, i);
}
cin >> m;
for (int i = 1; i <= m; i++) {
cin >> x;
if (index[x]) del(x);
}
int now = s[0].nxt; // dummy
while (now) {
printf("%d ", s[now].val);
now = s[now].nxt;
}
return 0;
}
当然,除了手写,我们也可以使用STL的<list>来实现。
index数组同样需要自己维护:
每次新增元素时,index[i] = prev(lst.end());。
#include <iostream>
#include <list>
#include <vector>
using namespace std;
int main() {
int n, m;
cin >> n;
list<int> lst; // 存储实际数据
vector<list<int>::iterator> index(n + 5, lst.end());
// index[i] 存储值 i 在链表中的迭代器
// 初始化:插入第一个人(值为1)
lst.push_back(1);
index[1] = prev(lst.end()); // 记录1的位置
// 插入后续同学
for (int i = 2; i <= n; i++) {
int k, p;
cin >> k >> p;
auto pos = index[k]; // 找到k的位置
if (p == 1) { // 插在k的右边
// 如果k是最后一个,直接push_back
if (next(pos) == lst.end()) {
lst.push_back(i);
index[i] = prev(lst.end());
} else {
auto next_pos = next(pos);
index[i] = lst.insert(next_pos, i);
}
} else { // 插在k的左边
index[i] = lst.insert(pos, i);
}
}
// 删除操作
cin >> m;
for (int i = 0; i < m; i++) {
int x;
cin >> x;
// 如果x存在且没有被删除过
if (index[x] != lst.end()) {
lst.erase(index[x]); // 从链表中删除
index[x] = lst.end(); // 标记为已删除
}
}
// 输出结果
for (auto val : lst) {
cout << val << " ";
}
cout << endl;
return 0;
}

#include <list>
空初始化、利用数组初始化,
大小、迭代器it、头插尾插、在it前插、头删尾删、删除it及元素(注意备份)、遍历。
这里很好的是可以练一练迭代器指针。
#include <iostream>
#include <cstdio>
#include <list>
using namespace std;
list<int> lst;
int main() {
int n, m, cnt = 0;
cin >> n >> m;
for (int i = 1; i <= n; i++) {
lst.push_back(i);
}
list<int>::iterator it = lst.begin(), now;
while (!lst.empty()) {
// 多计一个数, 准备看要不要删一个人
cnt++;
now = it; // now用于删除, 指向当前节点; it指向下一个节点
it++;
if (it == lst.end()) {
it = lst.begin();
}
if (cnt == m) {
cout << *now << ' ';
lst.erase(now);
cnt = 0;
}
}
return 0;
}

int ans = 0;
void play(int n) {
// 把函数逻辑的调用放入循环里, 一开始只是处理stk的初始放入
stack<int> stk; // 栈用于负责"函数调用的控制流".
stk.push(n);
while (!stk.empty()) {
// 获取函数参数
int current = stk.top(); stk.pop();
// 函数逻辑
ans += current;
if (current == 1 || current == 2) continue;
// 递归调用时先play(n-1)后play(n-2)
// 所以栈调用应为先压入n-2后压入n-1
stk.push(n - 2);
stk.push(n - 1);
}
}
让GPT生成了一个简单对拍验证一下,当然结果是正确的。

#include <iostream>
#include <stack>
using namespace std;
int ans = 0;
void play_stack(int n) {
stack<int> st;
// 初始调用
st.push(n);
while (!st.empty()) {
int current = st.top();
st.pop();
// 相当于递归中的 ans += n
ans += current;
// 相当于递归中的终止条件检查
if (current == 1 || current == 2) {
continue; // 不再继续展开
}
// 模拟递归调用:先 play(n-1),后 play(n-2)
// 因为栈是后进先出,所以要先压入 n-2,再压入 n-1
st.push(current - 2); // 第二调用
st.push(current - 1); // 第一调用
}
}
int main() {
// 测试
ans = 0;
play_stack(5);
cout << "play_stack(5) = " << ans << endl;
// 验证:与原递归比较
ans = 0;
// 原递归函数
auto play_recursive = [](auto&& self, int n) -> void {
ans += n;
if (n == 1 || n == 2) return;
self(self, n - 1);
self(self, n - 2);
};
ans = 0;
play_recursive(play_recursive, 5);
cout << "play_recursive(5) = " << ans << endl;
return 0;
}
二叉树专题

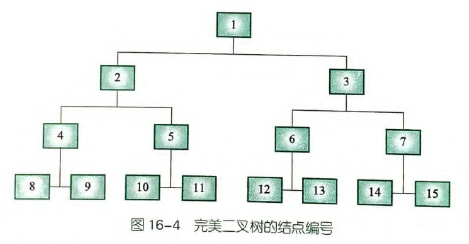
上图n=3,有8个国家参加,需要3轮比赛,高度为4。
下述知识包括完全二叉树的填表:如果叶子节点数量有 个,则叶子节点从 开始。
#include <iostream>
#include <cstdio>
using namespace std;
int value[260], winner[260];
int n;
// 调用时传入根节点, 但函数自底向上填表
void dfs(int x) {
if (x >= (1 << n)) return; // 叶子节点
dfs(2 * x);
dfs(2 * x + 1);
int lvalue = value[2 * x], rvalue = value[2 * x + 1];
if (lvalue > rvalue) {
value[x] = lvalue;
winner[x] = winner[2 * x];
} else {
value[x] = rvalue;
winner[x] = winner[2 * x + 1];
}
}
int main() {
cin >> n;
for (int i = 0; i < 1 << n; i++) {
// 叶子节点从1<<n开始, 到 1<<(n+1)-1
cin >> value[i + (1 << n)];
winner[i + (1 << n)] = i + 1;
}
dfs(1);
cout << value[2] > value[3] ? winner[3] : winner[2]; // 亚军
return 0;
}
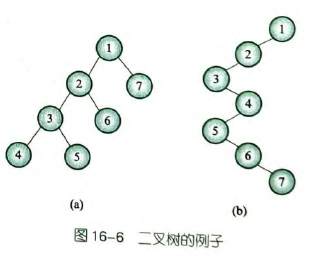
这是使用之前的孩子-双亲表示法的开法。
#include <iostream>
#include <cstdio>
#include <cmath>
using namespace std;
const int MAXN = 2e6 + 10;
int a[MAXN], n, l, r;
int dfs(int x) {
// 返回根为x的深度.
if (!x) return 0;
return 1 + max(dfs(a[2 * x]), dfs(a[2 * x + 1]));
}
int main() {
cin >> n;
for (int i = 1; i <= n; i++) {
scanf("%d%d", &l, &r);
a[2 * i] = l;
a[2 * i + 1] = r;
}
cout << dfs(1) << endl;
return 0;
}
也可以使用结构体充当链表。另外这道题实际范围开到 2e5 就能过。
#include <iostream>
#include <cstdio>
#include <cmath>
using namespace std;
const int MAXN = 2e5 + 10;
struct Node {
int l, r;
}t[MAXN];
int n;
int dfs(int x) {
// 返回根为x的深度.
if (!x) return 0;
return 1 + max(dfs(t[x].l), dfs(t[x].r));
}
int main() {
cin >> n;
for (int i = 1; i <= n; i++) {
scanf("%d%d", &t[i].l, &t[i].r);
}
cout << dfs(1) << endl;
return 0;
}
前中后序遍历:本质上是dfs时,visit在函数调用的前、中、后。


// eg. 前序: [1] 2 3 4 5 6 7
// 中序: 4 3 5 2 6 [1] 7
// 递归处理字符串序列即可
#include <iostream>
#include <cstdio>
#include <string>
using namespace std;
string a, b;
// 对一段前序序列和一段中序序列打印后序序列.
void build(int l1, int r1, int l2, int r2) {
// 根是a[l1]
for (int i = l2; i <= r2; i++) {
// 这个线性遍历可以优化成哈希
if (b[i] == a[l1]) {
// 对左子段和右子段进行build操作
// 后序, 所以先调两次build再打印根
// 左子段长度: i - l2, 例如上述是5
build(l1 + 1, l1 + i - l2, l2, i - 1);
build(l1 + i - l2 + 1, r1, i + 1, r2);
cout << b[i];
return;
}
}
}
int main() {
cin >> b >> a; // 草, P1827是先给了中序再给了前序
build(0, a.size() - 1, 0, b.size() - 1);
cout << endl;
return 0;
}

value: 值,size: 子树的节点个数,num: 该节点权值出现的次数(允许输入数据重复)。
#include <iostream>
#define MAXN 100010
using namespace std;
int n, root, cnt, opt, x;
struct Node {
int left, right, size, value, num;
Node(int l = 0, int r = 0, int s = 0, int v = 0) {
left = l;
right = r;
size = s;
value = v;
num = 1;
}
} t[MAXN];
inline void update(int root) {
if (!root) return;
t[root].size = t[t[root].left].size + t[t[root].right].size + t[root].num;
}
// 1. 查询数x的排名(小于x的个数 + 1)
// 书上的rank会出现函数引用歧义, 无法通过
int getrank(int x, int root) {
if (!root) return 1; // 空树,x应该是第1名
if (x < t[root].value) {
// x比当前节点小,进入左子树
return getrank(x, t[root].left);
}
else if (x > t[root].value) {
// x比当前节点大,进入右子树并且加上左子树的size和当前节点的数量
return t[t[root].left].size + t[root].num + getrank(x, t[root].right);
}
else { // x == t[root].value
// 找到x,排名是左子树大小 + 1
return t[t[root].left].size + 1;
}
}
// 2. 查询排名为x的数
int kth(int k, int root) {
if (!root) return -1;
int left_size = t[t[root].left].size;
if (k <= left_size) {
return kth(k, t[root].left);
}
else if (k <= left_size + t[root].num) {
return t[root].value;
}
else {
return kth(k - left_size - t[root].num, t[root].right);
}
}
// 3. 求x的前驱(小于x的最大数)
int predecessor(int x, int root) {
if (!root) return -2147483647;
if (t[root].value >= x) {
return predecessor(x, t[root].left);
}
else {
// 当前节点小于x,尝试在右子树找更大的(但仍小于x)
int right_result = predecessor(x, t[root].right);
if (right_result == -2147483647) {
return t[root].value; // 右子树没有更合适的,当前节点就是最大的
}
return max(t[root].value, right_result);
}
}
// 4. 求x的后继(大于x的最小数)
int successor(int x, int root) {
if (!root) return 2147483647;
if (t[root].value <= x) {
return successor(x, t[root].right);
}
else {
// 当前节点大于x,尝试在左子树找更小的(但仍大于x)
int left_result = successor(x, t[root].left);
if (left_result == 2147483647) {
return t[root].value; // 左子树没有更合适的,当前节点就是最小的
}
return min(t[root].value, left_result);
}
}
// 5. 插入一个数x(题目保证插入前x不在集合中)
void insert(int &root, int x) {
if (!root) {
root = ++cnt;
t[root] = Node(0, 0, 1, x);
return;
}
if (x < t[root].value) {
insert(t[root].left, x);
}
else if (x > t[root].value) {
insert(t[root].right, x);
}
else { // 根据题目要求,这里应该不会执行
t[root].num++;
}
update(root);
}
// 可选的删除操作(虽然题目没要求,但可以加上)
void remove(int &root, int x) {
if (!root) return;
if (x < t[root].value) {
remove(t[root].left, x);
}
else if (x > t[root].value) {
remove(t[root].right, x);
}
else { // 找到要删除的节点
if (t[root].num > 1) {
t[root].num--;
}
else {
// 节点只有一个或没有子节点
if (!t[root].left || !t[root].right) {
root = t[root].left + t[root].right;
}
else {
// 有两个子节点,找后继替换
int temp = successor(x, t[root].right);
t[root].value = temp;
remove(t[root].right, temp);
}
}
}
if (root) update(root);
}
int main() {
cin >> n;
root = 0; // 初始化根节点
while (n--) {
cin >> opt >> x;
switch(opt) {
case 1: // 查询x的排名
cout << getrank(x, root) << endl;
break;
case 2: // 查询排名为x的数
cout << kth(x, root) << endl;
break;
case 3: // 求x的前驱
cout << predecessor(x, root) << endl;
break;
case 4: // 求x的后继
cout << successor(x, root) << endl;
break;
case 5: // 插入x
insert(root, x);
break;
}
}
return 0;
}

每个节点存left, right, father和value。
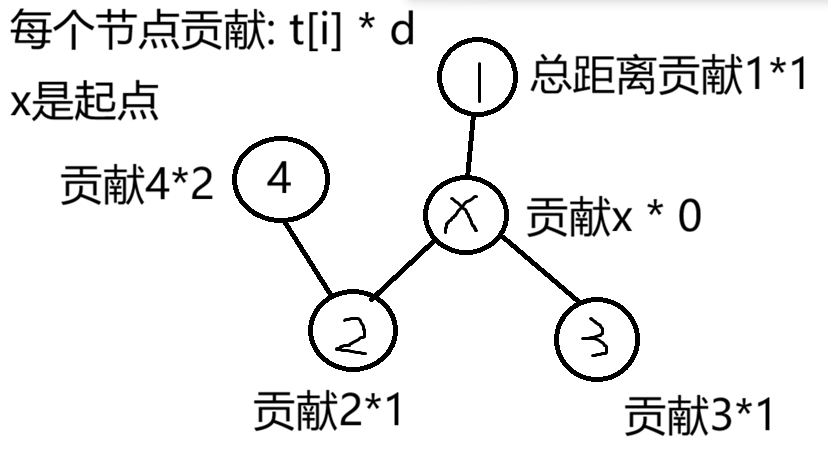
分析:对于某个特定节点修的医院,它的值就是所有节点到该节点的距离*人数之和,其实本质上就是求一个和的问题。
而对于特定节点到节点 i 的贡献,只与两个参数有关:距离 d 和人数 t[x] 。
因此,对和的贡献函数即是 cal(int x, int d) ,到节点 i 的和就是把所有的 cal 和 x 本身的贡献加起来,可以通过深度优先遍历实现。而对于节点 i 的总和其实就是 cal(i, 0) ,这会从节点 i 向外扩散求得总和。
而题目等价于在所有可能修成医院的节点中找和最小的。
#include <iostream>
#include <cstdio>
#include <cstring>
using namespace std;
#define MAXN 110
int vis[MAXN];
struct node {
int left, right, father, value;
} t[MAXN];
// 节点x到目标节点i的距离为d, 求它的贡献
int cal(int x, int d) {
if (!x || vis[x]) return 0;
vis[x] = 1;
// 自己的贡献加上向外调用
return cal(t[x].left, d + 1) + cal(t[x].right, d + 1) + cal(t[x].father, d + 1) + t[x].value * d;
}
int main() {
int n, ans = 2147483647;
cin >> n;
for (int i = 1; i <= n; i++) {
cin >> t[i].value >> t[i].left >> t[i].right;
t[t[i].left].father = i;
t[t[i].right].father = i;
}
for (int i = 1; i <= n; i++) { // ans = min_i cal(i, 0)
// 重要! 每次调cal(i, 0)遍历整个之前先清空vis
memset(vis, 0, sizeof(vis))
ans = min(ans, cal(i, 0));
}
cout << ans << endl;
return 0;
}
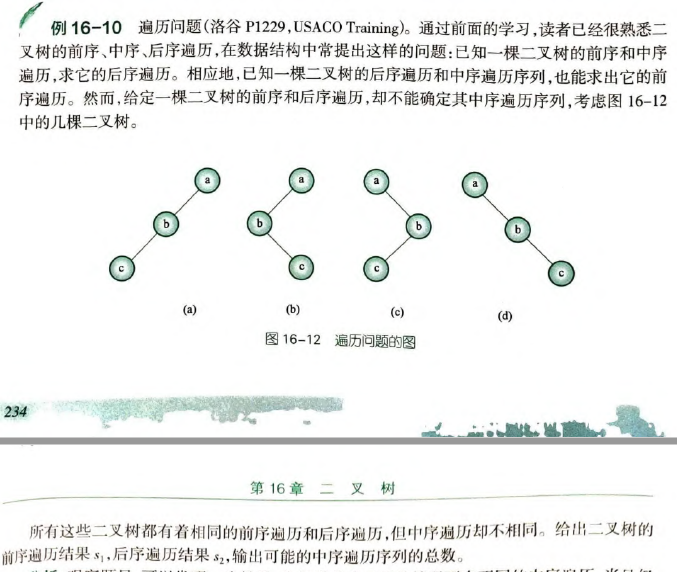
根左右,左右根:左右连一块了,有对称性;而左根右没有这样的对称性。
在知道前序后序的情况下有不同的中序遍历,当且仅当这个节点只有一个儿子,于是可以将问题转化为找只有一个儿子的节点个数。
如果在前序中出现AB、后序中出现BA,则这个节点一定只有一个儿子(因为前序后序只有根的位置不同,而且AB和BA当中必有一个是根),于是只要比较前序和后序序列,找满足AB和BA的个数即可。
假设有x个节点只有一个儿子,则它可能是左儿子或右儿子,也就是说共计有 种情况。于是答案是 种可能的二叉树,对应 种可能的中序遍历序列。
#include <iostream>
#include <string>
using namespace std;
const int MAXN = 100010;
int ans;
string a, b;
int main() {
cin >> a >> b;
int sz = a.size(); // = b.size
long long cnt = 0;
for (int i = 0; i < sz - 1; i++) {
for (int j = 1; j < sz; j++) {
if (a[i] == b[j] && a[i + 1] == b[j - 1]) {
cnt++;
}
}
}
cout << (1 << cnt) << endl;
return 0;
}
集合专题
知识


举例
并查集仅仅只是一个 fa 数组和两个函数。
其中最关键的是:路径压缩。(查询降低至 )
即find除了找到根,还要把一路上每一个节点的fa都设成根。

路径压缩的两种写法:
int find(int x) {
if (x == fa[x]) return x;
return fa[x] = find(fa[x]); // 递归+路径压缩
}
#include <iostream>
#include <cstdio>
using namespace std;
int n, m, p, x, y;
int fa[MAXN];
// 路径压缩
int find(int x) {
// 先找到根
int root = x;
while (root != fa[root]) {
root = fa[root];
}
// 然后把一路上的fa都设成根
// 注意为了防止丢失信息, 需要先拷贝再设置
while (x != root) {
int parent = fa[x];
fa[x] = root;
x = parent;
}
return root;
}
void join(int c1, int c2) {
// 注意这里是find不是fa
int f1 = find[c1], f2 = find[c2];
if (f1 != f2) fa[f1] = f2;
}
int main() {
cin >> n >> m >> p;
for (int i = 1; i <= n; i++) fa[i] = i;
for (int i = 0; i < m; i++) {
cin >> x >> y;
join(x, y);
}
for (int i = 0; i < p; i++) {
cin >> x >> y;
if (find(x) == find(y)) {
cout << "Yes" << endl;
} else {
cout << "No" << endl;
}
}
return 0;
}

相当于已有 w 个连通分支,将它们合并为 1 个连通分支需要多少次合并。
即答案为 w-1 个。
对于连通分支,方法是在合并的同时,记录有多少个代表元。
// 这里是例17-2, 而P1536由于测试用例格式略有区别, 见下
#include <iostream>
#include <cstdio>
using namespace std;
const int MAXN = 1010;
int fa[MAXN], n, x, y, cnt;
int find(int x) {
if (fa[x] == x) return x;
return fa[x] = find(fa[x]);
}
void merge(int x, int y) {
int fx = find(x), fy = find(y);
if (fx != fy) {
fa[fx] = fy;
cnt--; // 代表元数量-1
}
}
int main() {
cin >> n >> m;
cnt = n;
for (int i = 1; i <= n; i++) {
fa[i] = i;
}
for (int i = 0; i < m; i++) {
merge(x, y);
}
// 代表元数量为cnt, 即有cnt个连通分支
cout << cnt - 1 << endl;
return 0;
}
对于P1536,输入样例分好几组,需要修改main,
并且在每次输出完毕之后清空并查集。
eg. 输入#1分下述的四组,每组开头是 n 和 m ,接下来的 m 行是 m 条道路。
4 2
1 3
4 3
3 3
1 2
1 3
2 3
5 2
1 2
3 5
999 0
0
则修改为以下代码:
// P1536
#include <iostream>
#include <cstdio>
#include <cstring>
using namespace std;
const int MAXN = 1010;
int fa[MAXN], n, m, x, y, cnt;
int find(int x) {
if (fa[x] == x) return x;
return fa[x] = find(fa[x]);
}
void merge(int x, int y) {
int fx = find(x), fy = find(y);
if (fx != fy) {
fa[fx] = fy;
cnt--; // 代表元数量-1
}
}
int main() {
while (1) {
cin >> n;
if (n == 0) return 0;
memset(fa, 0, sizeof(fa));
cin >> m;
cnt = n;
for (int i = 1; i <= n; i++) {
fa[i] = i;
}
for (int i = 0; i < m; i++) {
cin >> x >> y;
merge(x, y);
}
// 代表元数量为cnt, 即有cnt个连通分支
cout << cnt - 1 << endl;
}
return 0;
}
开始介绍拉链法的哈希,本质上是哈希加上一个数组。

可以取一个模数,例如 23333 。(有趣的是,这个数以及 3 更少的都恰好是质数,但 233333 却不是)
以下是一个拉链法哈希的实现方式。
#include <iostream>
#include <vector>
#define mod 23333
using namespace std;
int n, x, ans;
vector<int> linker[mod + 2]; // vector的数组, 是一个"变长二维数组"
void insert(int x) {
for (int i = 0; i < linker[x % mod].size(); i++) {
if (linker[x % mod][i] == x) return; // 已存在
linker[x % mod].push_back(x);
ans++; // 统计不同数的个数
}
}
int main() {
cin >> n;
for (int i = 0; i < n; i++) {
cin >> x;
insert(x);
}
cout << ans << endl;
return 0;
}
当然,也可以直接使用集合 <set> 。
#include <iostream>
#include <set>
using namespace std;
set<int> ds;
int n, x;
int main() {
cin >> n;
while (n--) {
cin >> x;
ds.insert(x);
}
cout << ds.size() << endl;
return 0;
}

这里的知识重点是怎么把字符串转成哈希。
对于字符串哈希,在模数mod(23333)的基础上还引入了基数base(261)。

#include <iostream>
#include <string>
#include <vector>
#define MAXN 1510
#define mod 23333
#define base 261
using namespace std;
char s[MAXN];
int n, cnt = 0;
vector<string> linker[mod + 2];
inline void insert() {
int hash = 1;
for (int i = 0; s[i]; i++) {
// 1ll * hash * base + s[i]
hash = (1ll * hash * base + s[i]) % mod;
}
string t = s;
for (int i = 0; i < linker[hash].size(); i++) {
// 字符串已存在
if (linker[hash][i] == t) return;
}
linker[hash].push_back(t);
cnt++;
}
int main() {
cin >> n;
for (int i = 0; i < n; i++) {
cin >> s;
insert();
}
cout << cnt << endl;
return 0;
}
当然,如果不想好好练习哈希, 也可以使用 <set> 实现。
#include <iostream>
#include <set>
#include <string>
using namespace std;
int main() {
set<string> ds;
string s;
int n;
cin >> n;
while (n--) {
cin >> s;
ds.insert(s);
}
cout << ds.size() << endl;
return 0;
}

只用到前两个字母。
相当于统计 <ai, bi> == <aj, bj> 的数量。
方法是把 <ai, bi> 哈希到一个字符串,例如 MIFL 。
// x -> (哈希) -> x % mod -> (数组) -> linker[x % mod]
#include <iostream>
#include <vector>
#define mod 23333
using namespace std;
int n;
char a[12], b[12]; // 两个城市名
long long ans;
vector<pair<int, int>> linker[mod + 2]; // <字符串, 出现次数>
inline int gethash(char a[], char b[]) {
return (a[0]-'A') + (a[1]-'A')*26 + (b[0]-'A')*26*26 + (b[1]-'A')*26*26*26;
}
// 插入字符串x.
inline void insert(int x) {
for (int i = 0; i < linker[x % mod].size(); i++) {
if (linker[x % mod][i].first == x) {
linker[x % mod][i].second++;
break;
}
}
linker[x % mod].push_back(pair<int, int>(x, 1));
}
inline int find(int x) {
for (int i = 0; i < linker[x % mod].size(); i++) {
if (linker[x % mod][i].first == x) {
return linker[x % mod][i].second;
}
}
return 0;
}
int main() {
cin >> n;
for (int i = 1; i <= n; i++) {
cin >> a >> b;
a[2] = 0; // 只取前两个字符
if (a[0] != b[0] || a[1] != b[1]) {
ans += find(gethash(b, a));
}
insert(gethash(a, b));
}
cout << ans << endl;
return 0;
}

插入,存在,前驱,后继,删除。
这一块的迭代器真的很微妙:begin() 是闭的,而 end() 是开的,
导致你可以直接对 begin() 解引用、而 end() 不行,
除此之外当然不能对 begin() 进行 -- ,也不能对 end() 进行 ++ 。
#include <iostream>
#include <set>
using namespace std;
set<int> ds;
int main() {
int n, opt, x;
cin >> n;
while (n--) {
cin >> opt >> x;
if (opt == 1) {
if (ds.find(x) != ds.end()) {
cout << "Already Exist" << endl;
} else {
ds.insert(x);
}
} else {
if (ds.empty()) {
cout << "Empty" << endl;
} else if (ds.find(x) != ds.end()) {
cout << x << endl;
ds.erase(x);
} else {
// ds.lower_bound(x)是大于等于x的第一个元素
// (区别于upper_bound: 大于的第一个元素)
// 比较lower_bound和它前面的元素, 看哪个更接近x
auto i = ds.lower_bound(x), j = i;
if (j != ds.begin()) j--;
// 如果是ds.begin()则可以解引用而不能--,
// 如果是ds.end()则不能解引用
// (左闭右开)
if (i != ds.end() && (x - (*j) > (*i) - x)) j = i; // i更接近
cout << (*j) << endl;
ds.erase(j);
}
}
}
return 0;
}

#include <iostream>
#include <cstdio>
#include <map>
#include <string>
using namespace std;
map<string, int> ds;
int main() {
int q, opt, score;
string name;
cin >> q;
while (q--) {
cin >> opt;
if (opt == 1) {
cin >> name >> score;
ds[name] = score;
cout << "OK" << endl;
} else if (opt == 2) {
cin >> name;
if (ds.find(name) != ds.end()) {
cout << ds[name] << endl;
} else {
cout << "Not found" << endl;
}
} else if (opt == 3) {
cin >> name;
if (ds.find(name) != ds.end()) {
ds.erase(name);
cout << "Deleted successfully" << endl;
} else {
cout << "Not found" << endl;
}
} else {
cout << ds.size() << endl;
}
}
return 0;
}

#include <iostream>
#include <cstdio>
#include <unordered_map>
using namespace std;
const int MAXN = 200010;
unordered_map<int, int> ds;
int a[MAXN];
int main() {
long long ans;
int n, c;
cin >> n >> c;
for (int i = 0; i < n; i++) {
cin >> a[i];
ds[a[i]]++; // 输入并计数
}
for (int i = 0; i < n; i++) {
// 枚举A, 看A-C的个数
ans += ds[a[i] - c];
}
cout << ans << endl;
return 0;
}
图专题
在图里面,要干的事情是三件:
找到所有顶点,找到一个顶点有直接连接的每一个点,以及那条边的长度。
我愿称其为图的三件事:所有顶点,顶点邻接点,顶点邻接边。
邻接矩阵方便修改边权(随机访问),但是空间复杂度大。
邻接表不方便修改边权(需要遍历),但是空间复杂度小。

接下来干一下图的三件事:所有顶点,顶点邻接点,顶点邻接边。
邻接矩阵 数据结构定义:v[i][j]是从点 i 到点 j 的边权。
#include <iostream>
using namespace std;
const int MAXN = 1010;
int n;
int v[MAXN][MAXN];
// v[i][j]是从点i到点j的边权.
int main() {
cin >> n;
// 第一件事: 所有顶点即是v的行数或列数.
for (int i = 1; i <= n; i++) {
for (int j = 1; j <= n; j++) {
cin >> v[i][j];
}
}
// 第二件事: 找到每个顶点的所有邻接边及邻接点
for (int i = 1; i <= n; i++) {
for (int j = 1; j <= n; j++) {
if (v[i][j] > 0) {
cout << "edge from point" << i << " to point " << j << " with length " << v[i][j] << 'n';
}
}
}
return 0;
}
邻接表 数据结构定义:
一个变长二维数组装每个点邻接的所有边,每个边包括指向的点和边权。
(二维数组第一维为所有点,第二维为所有边)
可以简单理解:
p[x]是x的所有邻居组成的数组,我们要通过下标i遍历这个数组,所以是for i : p[x]。

#include <iostream>
#include <vector>
using namespace std;
const int MAXN = 1010;
struct edge {
int to, cost;
}
int n, m; // n个点, m条边
vector<edge> p[MAXN];
int main() {
cin >> n >> m;
for (int i = 1; i <= m; i++) {
int u, v, l;
cin >> u >> v >> l;
p[u].push_back((edge){v,l});
// p[v].push_back((edge){u,l}); // 无向图时还需要加一条这个
}
// 如果想把邻接表转换成邻接矩阵, 只需 v[i][p[i][j].to] = p[i][j].cost, 其中i是1到n的所有点,j是0到p[i].size()-1遍历变长数组所有边
return 0;
}
dfs:先设置vis,后调用dfs实现相应逻辑。
bfs:注意bfs中的vis是指是否入队,所以vis要在入队前标记。
而打印是通过取出队列元素实现bfs顺序,所以对节点的操作要写在循环体以内。
下述是P5318,多了一个条件:如果终点相同、需要按照入点排序。
#include <iostream>
#include <vector>
#include <queue>
#include <cstring>
#include <algorithm>
using namespace std;
const int MAXN = 100010;
vector<int> p[MAXN]; // 因为无权, edge退化成to即可
struct edge {
int from, to;
};
vector<edge> e; // 用于排序输入的边的临时数组
int n, m;
bool vis[MAXN];
queue<int> q;
bool cmp(edge x, edge y) {
if (x.to == y.to) return x.from < y.from;
return x.to < y.to;
}
void dfs(int x) {
// 按照dfs顺序, 输出节点.
cout << x << ' ';
int sz = p[x].size();
for (int i = 0; i < sz; i++) {
// 邻接节点是p[x][i]
if (!vis[p[x][i]]) {
vis[p[x][i]] = true;
dfs(p[x][i]);
}
}
}
void bfs(int x) {
// 按照bfs顺序, 输出节点.
vis[x] = true;
q.push(x);
while (!q.empty()) {
x = q.front(); q.pop();
cout << x << ' ';
int sz = p[x].size();
for (int i = 0; i < sz; i++) {
// 邻接节点是p[x][i]
if (!vis[p[x][i]]) {
vis[p[x][i]] = true;
q.push(p[x][i]);
}
}
}
}
int main() {
// 1. 建立图
cin >> n >> m;
for (int i = 1; i <= m; i++) {
int u, v; // 有向边(u, v)
cin >> u >> v;
e.push_back((edge){u, v});
}
sort(e.begin(), e.end(), cmp);
for (auto ee : e) {
p[ee.from].push_back(ee.to);
}
// 2. dfs
vis[1] = true;
dfs(1);
memset(vis, 0, sizeof(vis));
cout << endl;
bfs(1);
return 0;
}


要处理“遍历顺序”。
优先更新高编号、然后是低编号:“倒着找”。所以是反向边。
#include <iostream>
#include <vector>
using namespace std;
const int MAXN = 100010;
int n, m;
vector<int> p[MAXN]; // 图
int a[MAXN]; // 答案
// 更新以x为起点的一大片值.
void solve(int x, int v) {
a[x] = v;
for (int i = 0; i < p[x].size(); i++) {
if (a[p[x][i]] == 0) {
solve(p[x][i], v);
}
}
}
int main() {
cin >> n >> m;
for (int i = 1; i <= m; i++) {
int u, v;
cin >> u >> v;
p[v].push_back(u); // 优先更新高编号, 所以建反向边
}
for (int i = n; i >= 1; i--) { // 优先更新高编号
// 因为如果a[i]被更新, 则i指向的也一定全部完成更新
// 所以不需要再更新一次
if (a[i] == 0) solve(i, i);
}
for (int i = 1; i <= n; i++) {
cout << a[i] << ' ';
}
return 0;
}

完成每个任务的最短时间,
等于 其所有准备任务中最晚完成的时间 加上 完成该任务需要的时间 。
计算所有任务完成的最短时间,
转化为找DAG的一条最长链。
因为需要“倒着找”,还是建反向边。
#include <iostream>
#include <vector>
using namespace std;
const int MAXN = 10010;
int n, x, y, t, ans = -1, len[MAXN], vis[MAXN];
vector<int> linker[MAXN];
int dfs(int x) {
if (vis[x]) return vis[x];
for (int i = 0; i < linker[x].size(); i++) {
vis[x] = max(vis[x], dfs(linker[x][i]));
}
vis[x] += len[x];
return vis[x];
}
int main() {
cin >> n;
for (int i = 1; i <= n; i++) {
cin >> x >> len[i];
while (cin >> y) {
if (!y) break;
// 拓扑排序, 建反向边
else linker[y].push_back(x);
}
}
for (int i = 1; i <= n; i++) {
ans = max(ans, dfs(i));
}
cout << ans << endl;
return 0;
}


该题目相当于求DAG中最大链的个数。
拓扑排序:(不变量)队列里始终是入度为0的点。
每当取出一个点 x 时,遍历它指向的所有点。
对于被指的点,如点 y ,删去从 x 到 y 的边,并处理 x 对 y 的影响(如 f[y] = (f[x] + f[y]) % MOD)。
如果 y 的入度变为0时,将它加回队列。
对于该题目,首先把所有极大值点的 f 值置为1。
对于每个中间点,它的 f 值等于所有指向它的点的 f 值之和。
因此只需要拓扑排序遍历所有点(初始点为所有极大值点),并填充 f ,最后遍历所有极小值点得到链的个数即可。
#include <iostream>
#include <cstring>
#include <vector>
#include <queue>
#define MAXN 5010
#define MAXM 500010
#define MOD 80112002
using namespace std;
int n, m, ans = 0;
vector<int> p[MAXN];
queue<int> q;
int f[MAXN], ind[MAXN], outd[MAXN];
int main() {
cin >> n >> m;
for (int i = 1; i <= m; i++) {
int x, y;
cin >> x >> y;
outd[x]++;
ind[y]++;
p[x].push_back(y);
}
memset(f, 0, sizeof(f));
// 1. 遍历所有极大值点, 初始化.
for (int i = 1; i <= n; i++) {
if (ind[i] == 0) { // 遍历所有极大值点
f[i] = 1;
q.push(i);
}
}
// 2. 拓扑排序遍历所有非极大值点, 填表.
while (!q.empty()) {
int x = q.front(); q.pop();
for (int i = 0; i < p[x].size(); i++) {
// 删去一条边 (ind[y]--), 并处理x对y的影响
int y = p[x][i];
f[y] = (f[x] + f[y]) % MOD;
ind[y]--;
if (ind[y] == 0) q.push(y);
}
}
// 3. 遍历所有极小值点, 统计链的总数.
for (int i = 1; i <= n; i++) {
if (outd[i] == 0) ans = (ans + f[i]) % MOD;
}
cout << ans << endl;
return 0;
}
基础数学与数论
位运算与进制转换专题

先转到10进制,然后从十进制转到该进制。
n进制转换为10进制:先乘以基数再加offset,即
*和+。
10进制转换为m进制:先取offset再除以基数,即%和/=。
n进制转10进制:从左往右“扫描”,将已经有的数字乘以进制(如16)(或者理解为“左移”),新扫描到的数字作为offset加入。
10进制转n进制:从右往左“添加”,将已经有的数字取出offset(如16),然后剩下的数字除以进制(或者理解为“右移”),得到逆序。
#include <iostream>
#include <string>
using namespace std;
// 1-10,ABCDEF转成数字
int c2i(char a) { // char to int
if ('0' <= a && a <= '9') return a - '0';
else return 10 + a - 'A';
}
char i2c(int a) {
// 这里写 0 <= a <= 9 不行, 原因不明
if (a <= 9) return '0' + a;
else return a - 10 + 'A';
}
int main() {
int output[33]; // 最长的是二进制数, 根据题目含义不超过2147483647, 所以32"位"足够了
int n, m, dec = 0, num = 0;
string input;
cin >> n >> input >> m;
// n进制转换为10进制
// eg. 3 * 16^2 + 2 *16^1 + 1
// = 16 * (16 * (16 * 0 + 3) + 2) + 1
// 相当于先乘以基数再加offset
for (int i = 0; i < input.length(); i++) {
dec = dec * n + c2i(input[i]);
}
// 10进制转换为m进制
// 相当于先取offset再除以基数
// 注意此时得到的是逆序的
while (dec != 0) {
output[num++] = dec % m;
dec /= m;
}
for (int i = num - 1; i >= 0; i--) {
cout << i2c(output[i]);
}
cout << endl;
return 0;
}
计数原理与排列组合专题


选择最局限的兔子要先选,是因为如果其他兔子先选,可能出现选择最局限的兔子无牌可选的情况,该情况无解,使得相关的计算变复杂。
而如果我们让选择最局限的兔子先选时,构造出的一定是可行解。
更严格的数学证明讨论个人不是很明确,欢迎感兴趣的朋友在评论区交流。
#include <iostream>
#include <algorithm>
#define MOD 1000000007
using namespace std;
int main() {
int n, i, num[51];
long long ans = 1;
cin >> n;
for (int i = 0; i < n; i++) cin >> num[i];
sort(num, num + n);
for (int i = 0; i < n; i++) {
ans *= (num[i] - i);
ans %= MOD;
}
cout << ans << endl;
return 0;
}
打组合数表。方法是借助递推: , 。
#include <iostream>
using namespace std;
long long c[25][25];
int main() {
cin >> n >> m;
// 递推
for (int i = 0; i <= 21; i++) {
c[i][0] = 1;
c[i][i] = 1;
for (int j = 1; j < i; j++) {
c[i][j] = c[i - 1][j - 1] + c[i - 1][j];
}
}
/* 输出杨辉三角
for (int i = 0; i <= 20; i++) {
for (int i = 0; j <= i; j++) {
cout << c[i][j] << ' ';
}
cout << endl;
}*/
// 输出题设需要的c[n][m]
cout << c[n][m] << endl;
return 0;
}
在杨辉三角打表的同时,对 取模。


#include <iostream>
#include <algorithm>
using namespace std;
long long c[2010][2010];
int main() {
int t, k, m, n;
cin >> t >> k;
for (int i = 0; i <= 2000; i++) {
c[i][0] = c[i][i] = 1;
for (int j = 1; j < i; j++) {
c[i][j] = (c[i - 1][j - 1] + c[i - 1][j]) % k;
}
}
while (t--) {
int ans = 0;
cin >> n >> m;
for (int i = 0; i <= n; i++) {
for (int j = 0; j <= min(i, m); j++) {
ans += c[i][j] == 0;
}
}
cout << ans << endl;
}
return 0;
}
整除理论专题
知识
和 的最大公约数记为 ,最小公倍数记为 。



举例
添加了新的工具:枚举约数。
方法是从 枚举到 。

#include <iostream>
using namespace std;
int find_divisors(int n, int a[]) {
// a用来存储n的所有约数 (无序, 从0开始) , 返回值为约数个数
int cnt = 0;
for (int k = 1; k <= n / k; k++) {
// 考虑到k*k可能爆long long, 可以写为 k <= n / k
if (n % k == 0) {
a[cnt++] = k;
if (k != n / k) a[cnt++] = n / k; // 成对出现
}
}
return cnt;
}
int main() {
int n = 120;
int a[32];
int cnt = find_divisors(n, a);
cout << cnt << endl;
for (int i = 0; i < cnt; i++) {
cout << a[i] << ' ';
}
cout << endl;
return 0;
}

例如原长度为12,则找约数是 的,枚举检验长度为1, 2, 3, 4, 6, 12的字符串是 的,其中 是约数个数6。


如果枚举每对数, 。
如果枚举约数,找每个数的约数是 的( 代表数组 中所有数中约数最多的数),在找的同时对每个数是否存在进行确认是 的(哈希),总共 个数,所以是 。
如果枚举倍数,每个数出现的次数相当于它对每个倍数做的贡献。事实上,是 的,因为外层循环的变量大小会影响内层循环的步长,使得时间复杂度为 。
#include <cstdio>
using namespace std;
#define MAXN 1000010
int n, a[MAXN], c[MAXN], w[MAXN]; // 数列中的数字, 数字计数, 计算贡献
int main() {
scanf("%d", &n);
for (int i = 1; i <= n; i++) {
scanf("%d", &a[i]);
c[a[i]]++;
}
for (int i = 1; i <= 1000000; i++) {
for (int j = i; j <= 1000000; j += i) {
w[j] += c[i];
}
}
for (int i = 1; i <= n; i++) {
// 减掉a[i]对自己的贡献
printf("%d\n", w[a[i]] - 1);
}
return 0;
}

先通过线性筛(埃氏筛)打素数表,然后对输入的数查表。
// 这是书上通过Yes或No判断某个数是否为素数的代码
#include <cstdio>
using namespace std;
#define MAXN 10000010
int n, N, x;
bool a[MAXN]; // true: 不是素数
int main() {
a[0] = a[1] = 1;
scanf("%d", &N);
for (int i = 2; i <= N / i; i++) {
if (a[i] == 0) {
for (int j = 2 * i; j <= N; j += i) {
a[j] = 1;
}
}
}
scanf("%d", &n);
while (n--) {
scanf("%d", &x);
if (a[x]) {
printf("No\n");
} else {
printf("Yes\n");
}
}
return 0;
}
对于P3383,已更新为查第k小的素数。
变式很简单,在打表的同时,用另外一个数组存下第k小的素数。
注意大小增大到了 。下述两个数组经过O2优化之后,实际开下来大概110M,在题目限制的512M范围内。
// 这是P3383
#include <cstdio>
using namespace std;
#define MAXN 100000010
int n, N, x;
bool a[MAXN]; // true: 不是素数
int p[MAXN], cnt = 0; // 素数
int main() {
a[0] = a[1] = 1;
scanf("%d", &N);
for (int i = 2; i <= N; i++) {
if (a[i] == 0) { // 是素数
for (int j = 2 * i; j <= N; j += i) {
a[j] = 1;
}
p[++cnt] = i;
}
}
scanf("%d", &n);
while (n--) {
scanf("%d", &x);
printf("%d\n", p[x]);
}
return 0;
}

#include <cstdio>
#include <cstring>
#include <algorithm>
// max在algorithm
using namespace std;
#define MAXN 1000010
typedef long long LL;
int n, N, x, pri[10000];
bool a[MAXN]; // 为0则是素数
int sieve(int n, int pri[]) {
for (int i = 2; i <= n / i; i++) {
if (a[i] == 0) {
for (int j = 2 * i; j <= n; j += i) {
a[j] = 1;
}
}
}
int cnt = 0;
for (int i = 2; i <= n; i++) {
if (!a[i]) pri[cnt++] = i;
}
return cnt;
}
int main() {
int cnt = sieve(50000, pri);
LL L, R;
scanf("%lld %lld", &L, &R);
memset(a, 0, sizeof(a));
if (L <= 1ll) {
a[0] = 1; // 注意初始化. 应对新增的hack数据1 3
}
for (int i = 0; i < cnt; i++) {
LL val = (L - 1) / pri[i] + 1;
LL j = max(2ll, val) * pri[i];
for (; j <= R; j += pri[i]) {
a[j - L] = 1;
}
}
int ans = 0;
for (LL i = L; i <= R; i++) {
if (a[i - L] == 0) ans++;
}
printf("%d", ans);
return 0;
}
求最大公约数:辗转取模。
求最小公倍数:利用乘积除以最大公约数。







#include <cstdio>
using namespace std;
int gcd(int x, int y) {
return y ? gcd(y, x % y) : x;
}
int x, y, P, Q, cnt;
int main() {
scanf("%d%d", &x, &y);
for (int k = 1; k <= y / k; k++) {
if (y % k == 0) {
if (gcd(k, y / k * x) == x) cnt++;
if (y / k != k) {
if (gcd(y / k, k * x) == x) cnt++;
}
}
}
printf("%d", cnt);
return 0;
}

#include <cstdio>
using namespace std;
int gcd(int x, int y) {
return y ? gcd(y, x % y) : x;
}
int lcm(int x, int y) {
return x / gcd(x, y) * y;
}
int T, a0, a1, b0, b1;
int main() {
scanf("%d", &T);
while (T--) {
int cnt = 0;
scanf("%d%d%d%d", &a0, &a1, &b0, &b1);
for (int x = 1; x <= b1 / x; x++) {
if (b1 % x == 0) {
if (gcd(x, a0) == a1 && lcm(x, b0) == b1) cnt++;
if (b1 / x != x) {
if (gcd(b1 / x, a0) == a1 && lcm(b1 / x, b0) == b1) cnt++;
}
}
}
printf("%d\n", cnt);
}
return 0;
}

#include <bits/stdc++.h>
using namespace std;
#define MAXN 10010
int m1, m2, n, pri[MAXN], tot[MAXN], a[MAXN];
int Decomposition(int x) {
int cnt = 0, Cnt = 0;
for (int i = 2; i <= x / i; i++) {
for (; x % i == 0; x /= i) {
a[++cnt] = i;
}
}
if (x > 1) a[++cnt] = x;
for (int i = 1; i <= cnt; i++, tot[Cnt]++) { // tot记录对应质数的次数
if (a[i] != a[i - 1]) pri[++Cnt] = a[i]; // pri记录m1中出现的质数
}
return Cnt;
}
int main() {
scanf("%d%d%d", &n, &m1, &m2);
int cnt = Decomposition(m1), ans = 2e9, s;
while (n--) {
scanf("%d", &s);
int x = 0;
for (int i = 1; i <= cnt; i++) {
int p = pri[i];
if (s % p != 0) { // 说明这个数没有p这个质因子, 不符合要求
x = -1;
break;
} else {
int e = 0;
for (; s % p == 0; s /= p) {
e++; // 统计这个质因子出现了几次
}
x = max(x, 1 + (m2 * tot[i] - 1) / e); // 计算对应的x
}
}
if (x >= 0) ans = min(ans, x); // 注意: x = 0是可行的
}
if (ans >= 2e9) puts("-1");
else printf("%d", ans);
return 0;
}

初步学习完结撒花!