【数据结构与算法5】LeetCode HOT 100 in Python(后50)
回溯、二分查找、栈、堆、贪心、动态规划、多维动态规划、技巧。
大致目的是完整地、成体系地过,
然后对关键点仔细地、反复地揣摩把握,
最终目标是任意抽出一道、均能有很好的理解。
专题10 回溯
专题11 二分查找
专题12 栈
专题13 堆
专题14 贪心
专题15 动态规划
专题16 多维动态规划
专题17 技巧
专题10 回溯
46 全排列
回溯模板:结束条件,遍历选择,做出选择。
class Solution:
def permute(self, nums: List[int]) -> List[List[int]]:
res = []
# 回溯: 结束, 遍历, 选择
def backtrack(path, used):
if len(path) == len(nums):
res.append(path[:])
for i in range(len(nums)):
if used[i]:
continue
path.append(nums[i])
used[i] = True
backtrack(path, used)
path.pop()
used[i] = False
backtrack([], [False] * len(nums))
return res
78 子集
回溯需要考虑当前start时可以做哪些选择。
class Solution:
def subsets(self, nums: List[int]) -> List[List[int]]:
res = []
def backtrack(start, path):
res.append(path[:])
for i in range(start, len(nums)):
path.append(nums[i])
backtrack(i + 1, path)
path.pop()
backtrack(0, [])
return res
17 电话号码的字母组合
回溯需要考虑当前位置可以做出哪些选择。
class Solution:
def letterCombinations(self, digits: str) -> List[str]:
adict = {'2': 'abc', '3': 'def', '4': 'ghi', '5': 'jkl', '6': 'mno', '7': 'pqrs', '8': 'tuv', '9': 'wxyz'}
res = []
def backtrack(path, cur):
if cur == len(digits):
res.append(''.join(path[:]))
return
for choice in adict[digits[cur]]:
path.append(choice)
backtrack(path, cur + 1)
path.pop()
backtrack([], 0)
return res
39 组合总和
(集合中元素可以重复使用,不同位置元素不同)
重复使用通过传入相同的i实现。
class Solution:
def combinationSum(self, candidates: List[int], target: int) -> List[List[int]]:
res = []
def backtrack(path, cur, start):
if cur == 0:
res.append(path[:])
return
for i in range(start, len(candidates)):
if candidates[i] > cur:
continue
path.append(candidates[i])
backtrack(path, cur - candidates[i], i) # 细节: 可以重复使用, 所以是i
path.pop()
candidates.sort() # 排序优化剪枝
backtrack([], target, 0)
return res
变式:组合总和II
(集合中每个元素只能重复使用一次,不同位置可能有相同元素)
关键:只能使用一次通过传入i+1实现,不同位置可能有相同元素通过排序后连续元素剪枝实现。
class Solution:
def combinationSum2(self, candidates: List[int], target: int) -> List[List[int]]:
res = []
def backtrack(path, start, remaining):
if remaining == 0:
res.append(path[:])
return
for i in range(start, len(candidates)):
if candidates[i] > remaining: # 剪枝
return
if i > start and candidates[i] == candidates[i - 1]:
continue
path.append(candidates[i])
backtrack(path, i + 1, remaining - candidates[i]) # 细节: i + 1
path.pop()
candidates.sort()
backtrack([], 0, target)
return res
22 括号生成
回溯选择:如果左括号数量不到n,则可以加左括号;如果右括号数量少于左括号(当然也不到n),则可以加右括号。
class Solution:
def generateParenthesis(self, n: int) -> List[str]:
res = []
def backtrack(path, left, right):
if len(path) == 2 * n:
res.append(''.join(path))
# 可以加左括号的条件
if left < n:
path.append('(')
backtrack(path, left + 1, right)
path.pop()
# 可以加右括号的条件: 右括号数量小于左括号数量
if right < left:
path.append(')')
backtrack(path, left, right + 1)
path.pop()
backtrack([], 0, 0)
return res
79 单词搜索
退出条件,保存,选择,回溯。
class Solution:
def exist(self, board: List[List[str]], word: str) -> bool:
m, n = len(board), len(board[0])
dirs = [(-1, 0), (1, 0), (0, -1), (0, 1)]
def backtrack(i, j, cur):
if cur == len(word):
return True
if i < 0 or i >= m or j < 0 or j >= n or board[i][j] != word[cur]:
return False
tmp = board[i][j]
board[i][j] = '#'
found = 0
for dx, dy in dirs:
nx, ny = i + dx, j + dy
found += backtrack(nx, ny, cur + 1)
board[i][j] = tmp
return found != 0
for i in range(m):
for j in range(n):
if backtrack(i, j, 0):
return True
return False
131 分割回文串
class Solution:
def partition(self, s: str) -> List[List[str]]:
res = []
def backtrack(start, path):
if start == len(s):
res.append(path[:])
for end in range(start, len(s)):
subs = s[start:end + 1]
if subs[::-1] == subs:
path.append(subs)
backtrack(end + 1, path)
path.pop()
backtrack(0, [])
return res
51 N皇后
仍然是回溯的结束条件、遍历选择空间、做出选择的三步走。
对于N皇后问题,为了简化,我们用回溯函数代表处理特定行(此时排除掉了各行重复的问题),然后对于该函数,遍历所有列作为可能的选择,通过cols、diag1和diag2三个集合作为排除选择的条件。
N皇后的行条件自动保证,列条件有n个(通过col是否存在确定),主对角线有2n-1个(row - col的取值范围是从-(n-1)到(n-1)),副对角线有2n-1个(row + col的取值范围是从2到2n)。通过set是否存在即可。
class Solution:
def solveNQueens(self, n: int) -> List[List[str]]:
res = []
board = [['.'] * n for _ in range(n)]
cols = set()
diag1 = set()
diag2 = set()
def backtrack(row):
if row == n:
res.append([''.join(board_row) for board_row in board])
return
for col in range(n):
if col in cols or (row - col) in diag1 or (row + col) in diag2:
continue
# 做选择
board[row][col] = 'Q'
cols.add(col)
diag1.add(row - col)
diag2.add(row + col)
backtrack(row + 1)
board[row][col] = '.'
cols.remove(col)
diag1.remove(row - col)
diag2.remove(row + col)
backtrack(0)
return res
239 滑动窗口最大值
发现之前有一道滑动窗口的题忘了做了。
首先挨个元素推入最大堆。在最大堆中元素足够多时,将不在窗口的全部pop出来,则剩下的就是在窗口内、且值最大的元素。
堆通过heapq包对heap数组进行处理,两个方法分别叫做heapq.heappush和heapq.heappop。
class Solution:
def maxSlidingWindow(self, nums: List[int], k: int) -> List[int]:
# 最大堆, 所以存储 (-num, i)
# 堆顶是heap[0]
heap = []
result = []
for i, num in enumerate(nums):
heapq.heappush(heap, (-num, i))
if i >= k - 1:
# 已存入长度为k的元素
# 窗口应该是 [i - k + 1, i] 这k个元素
while heap and heap[0][1] <= i - k:
heapq.heappop(heap)
result.append(-heap[0][0])
return result
更好的做法是维护一个单调队列:
目标是:队头始终是窗口内的最大元素。
每次加入新元素前,将队尾小于新元素的全部移除。(不可能成为最大值)
加入后、添加res前,将队头不在窗口内的全部移除。
(单调队列一般就是这种移除队尾的小元素的写法用法,然后因为这里有窗口的要求、还需要移除队头不在窗口内的元素。)
class Solution:
def maxSlidingWindow(self, nums: List[int], k: int) -> List[int]:
# 维护单调队列
# 每次都首先移除队尾比它小的元素, 然后再加入, 这样就会使得队列始终是单调递减的
q = deque()
res = []
for i, num in enumerate(nums):
# 移除队尾比num小的元素
while q and q[-1][1] < num:
q.pop()
q.append((i, num))
# 移除队头不在窗口内的元素
while q and q[0][0] <= i - k:
q.popleft()
if i >= k - 1:
res.append(q[0][1])
return res
专题11 二分查找
35 搜索插入位置
bisect的两个函数分别叫bisect_left和bisect_right。
它们的特点是,你把新元素插入到它返回的位置,数组仍然保持有序。
如果元素已存在,则left返回已存在元素的第一个位置,right返回已存在元素的最后一个位置的下一个位置。
class Solution:
def searchInsert(self, nums: List[int], target: int) -> int:
return bisect.bisect_left(nums, target)
74 搜索二维矩阵
用二分查找的话就是对每行搜索一下。
需要注意的是,很有可能返回的下标为n(未找到,且待寻找元素比该行都要大),所以顺手加个条件。
class Solution:
def searchMatrix(self, matrix: List[List[int]], target: int) -> bool:
m, n = len(matrix), len(matrix[0])
for i in range(m):
j = bisect.bisect_left(matrix[i], target)
if j < n and matrix[i][j] == target:
return True
return False
34 在排序数组中查找元素的第一个和最后一个位置
class Solution:
def searchRange(self, nums: List[int], target: int) -> List[int]:
n = len(nums)
l = bisect.bisect_left(nums, target)
if l >= n or nums[l] != target:
return [-1, -1]
r = bisect.bisect_right(nums, target) - 1
return [l, r]
33 搜索旋转排序数组
这个需要判断出左边一段有序还是右边一段有序。
因为找到有序的段之后,就可以通过和区间两个端点比较,确定target是否在这一段有序区间内。
class Solution:
def search(self, nums: List[int], target: int) -> int:
l, r = 0, len(nums) - 1
while l <= r:
mid = (l + r) // 2
if nums[mid] == target:
return mid
if nums[l] <= nums[mid]:
# 这一段有序, 则可以通过和两个端点比较确定target是否在这一段内
if nums[l] <= target < nums[mid]:
r = mid - 1
else:
l = mid + 1
else:
if nums[mid] < target <= nums[r]:
l = mid + 1
else:
r = mid - 1
return -1
153 寻找旋转排序数组中的最小值
还是一样的道理,旋转排序数组通过判断哪半段区间是有序的,来解决问题。另外那一半无序的区间只需要通过移动端点逼近处理即可。
class Solution:
def findMin(self, nums: List[int]) -> int:
l, r = 0, len(nums) - 1
minVal = nums[0]
while l <= r:
mid = (l + r) // 2
if nums[mid] < minVal:
minVal = min(minVal, nums[mid])
else:
if nums[l] <= nums[mid]:
# 有序
minVal = min(minVal, nums[l])
l = mid + 1
else:
minVal = min(minVal, nums[mid + 1])
r = mid - 1
return minVal
4 寻找两个正序数组的中位数
这个的思想是,找到给两个数组切开的位置,使得切痕左边的整体,小于等于切痕右边的整体。并且,这两段整体大小相同。
实现方法是,将nums1左边的元素数量(切痕位置)作为二分查找的变量,然后通过左边整体的个数(两个数组总数的一半,向上取整)减去这个数量得到nums2左边的元素数量。
在二分基础上,加上了上取整、数组越界等细节。
class Solution:
def findMedianSortedArrays(self, nums1: List[int], nums2: List[int]) -> float:
# 在nums1某处切一刀, nums2某处切一刀
# 使得两刀左边整体都比右边整体小.
# 二分查找确定nums1要取的元素个数i, 然后左半部分元素个数应该恰好均分, 从而确定nums2要取的元素个数j.
# 假如数组长度是5+6,则左半总共6个.
# 假如数组长度是5+5, 则左半总共5个.
if len(nums1) > len(nums2):
nums1, nums2 = nums2, nums1
m, n = len(nums1), len(nums2)
# 左半的元素总数, 上取整, 从而使得中位数基本上落入左半边
total_left = (m + n + 1) // 2
l, r = 0, m # i最少取0个, 最多取m个, 要确定所取个数
while l <= r:
i = (l + r) // 2
j = total_left - i
lmax_1 = float('-inf') if i == 0 else nums1[i - 1]
rmin_1 = float('inf') if i == m else nums1[i]
lmax_2 = float('-inf') if j == 0 else nums2[j - 1]
rmin_2 = float('inf') if j == n else nums2[j]
if lmax_1 <= rmin_2 and lmax_2 <= rmin_1: # 已找到
if not (m + n) % 2:
return (max(lmax_1, lmax_2) + min(rmin_1, rmin_2)) / 2
else:
return max(lmax_1, lmax_2)
elif lmax_1 > rmin_2:
r = i - 1
else:
l = i + 1
return 0
专题12 栈
20 有效的括号
注意在使用下标前先做是否为空的判断,这个是容易漏掉的。
class Solution:
def isValid(self, s: str) -> bool:
stk = []
for c in s:
if c == '(' or c == '[' or c == '{':
stk.append(c)
elif c == ')':
if stk and stk[-1] == '(':
stk.pop()
else:
return False
elif c == ']':
if stk and stk[-1] == '[':
stk.pop()
else:
return False
elif c == '}':
if stk and stk[-1] == '{':
stk.pop()
else:
return False
if stk:
return False
else:
return True
155 最小栈
如果要有额外的功能,则添加额外的数据结构。
class MinStack:
def __init__(self):
# 两个结构各自实现栈和最小
self.stk = []
self.minStk = []
def push(self, val: int) -> None:
self.stk.append(val)
i = bisect.bisect_left(self.minStk, val)
self.minStk.insert(i, val)
def pop(self) -> None:
val = self.stk.pop()
i = bisect.bisect_left(self.minStk, val)
self.minStk.pop(i)
def top(self) -> int:
return self.stk[-1]
def getMin(self) -> int:
return self.minStk[0]
# Your MinStack object will be instantiated and called as such:
# obj = MinStack()
# obj.push(val)
# obj.pop()
# param_3 = obj.top()
# param_4 = obj.getMin()
394 字符串解码
首先不考虑递归的情况即可。考虑最简单的例子:
3[a]2[b]
对于字符串解码,它肯定是从左往右读的。
(1) 读到数字时构造当前数字这个简单,
(2) 读到字符时构造当前字符串。
需要稍微仔细考虑一下的是读到 [ 和 ] 的情况。
(3) 假如说前面已经解码出了 aaa,在读到 [ 时,应该把 aaa存入栈中,作为等待连接起来的前置字符串,然后就可以开始构造 [] 里面的字符串了。
(4) 在读到 ] 时,展开当前一段的全部所需信息已经满足,只要把前置字符串取出,然后展开即可。
再考虑递归的情况:
每当读到 ] 时,就可以把栈中存的前面某一段给拼进来。
class Solution:
def decodeString(self, s: str) -> str:
numStk = []
strStk = []
curNum = 0
curStr = ''
for c in s:
if c.isdigit():
curNum = 10 * curNum + int(c)
elif c == '[':
# 构造完毕, 当前数字和字符串入栈
numStk.append(curNum)
strStk.append(curStr) # 临时存放, 便于一会取出作为prevStr
curNum = 0
curStr = ''
elif c == ']':
repeat_times = numStk.pop()
prevStr = strStk.pop()
curStr = prevStr + curStr * repeat_times
else:
curStr += c
return curStr
739 每日温度
当当前温度高于栈顶的一系列温度时,取出它们的下标,将相应下标位置置为下标差。
class Solution:
def dailyTemperatures(self, temperatures: List[int]) -> List[int]:
stk = []
res = [0] * len(temperatures)
for i, temp in enumerate(temperatures):
while stk and stk[-1][1] < temp:
cur_i, _ = stk.pop()
res[cur_i] = i - cur_i
stk.append((i, temp))
return res
84 柱状图中最大的矩形
这个单调栈问题如果有一些直观直觉,会好把握一点。
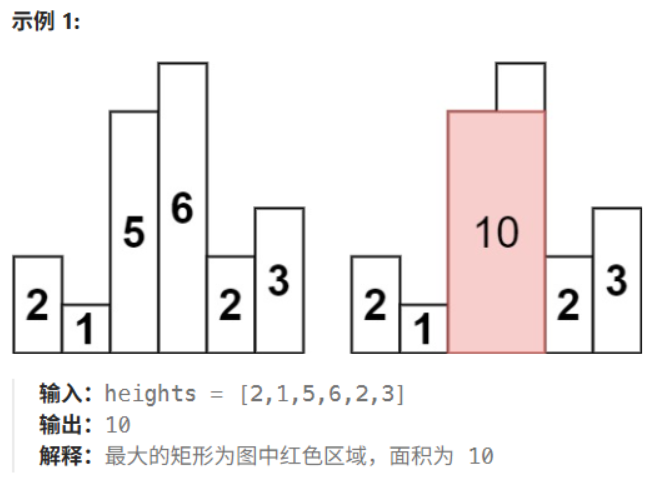
例如图上 [2,1,5,6,2,3] 的情况,我们可以有直观直觉:两边很矮,然后中间连着有几个高的,这样会有比较大的矩形。
单调栈正是为了实现这个直觉,比如中间连着的几个高的不再会用在以后的大矩形中(因为有右边的矮高度隔开)。
而左边的矮的不会用在现在的大矩形中,而是用在以后的长条矩形中,所以作为左边界、在栈里面存着。
如果高度为升序则直接存入,
一旦有逆序则i即为右边界,
通过弹出直到找到左边界(不再逆序)来确定面积。
至于为什么是升序:
首先一开始是宽度为1、高度为最高(单调栈栈顶),
随着宽度扩大,高度只会慢慢变低,我们不能直接由宽度和高度同时变大或变小来确定面积肯定变大或变小,因此只遍历判断这些情况是效率最高的。
就像2,1,5,6,2,3这样的情况中的面积应为1,5,6,2围出的10,右边界是通过6,2得到的逆序,左边界是通过1,2得到的不再逆序。
在完成一次右边界判断后,右边界加入栈中,则5和6不再对以后的最大面积有意义,因此在这个过程中也是弹出的。
class Solution:
def largestRectangleArea(self, heights: List[int]) -> int:
heights = [0] + heights + [0]
stack = []
# 如果高度为升序则直接存入
# 一旦有逆序即找到右边界
# 通过弹出直到找到左边界来确定面积
max_area = 0
for i in range(len(heights)):
# 满足栈顶大于nums[i]时, i即为右边界
# 满足栈中指向的某个元素小于nums[i]时, 该元素即为左边界
while stack and heights[i] < heights[stack[-1]]:
height = heights[stack.pop()]
width = i - stack[-1] - 1
max_area = max(max_area, height * width)
stack.append(i)
return max_area
专题13 堆
215 数组中的第K个最大元素
class Solution:
def findKthLargest(self, nums: List[int], k: int) -> int:
nums.sort()
return nums[-k]
建堆是O(n)的,这事一眼看到还是有一点反直觉的。
class Solution:
def findKthLargest(self, nums: List[int], k: int) -> int:
nums = [-x for x in nums]
heapq.heapify(nums)
for i in range(k - 1):
heapq.heappop(nums)
return -heapq.heappop(nums)
347 前K个高频元素
第一种方法当然是按照频率降序排序,然后取前k个。
说起来以前对key的理解不够时不太能理解lambda函数。自从意识到key是任意的单参数函数、返回一个可比较的值之后,就很明确了。
class Solution:
def topKFrequent(self, nums: List[int], k: int) -> List[int]:
freq = defaultdict(int)
for num in nums:
freq[num] += 1
items = list(sorted(freq.items(), key = lambda x: -x[1]))
return [x[0] for x in items[:k]]
当然也可以拿堆去做。
class Solution:
def topKFrequent(self, nums: List[int], k: int) -> List[int]:
freq = defaultdict(int)
for num in nums:
freq[num] += 1
items = [(-f, v) for v, f in freq.items()]
heapq.heapify(items)
res = []
for i in range(k):
res.append(heapq.heappop(items)[1])
return res
295 数据流的中位数
方法是维护一个最大堆和一个最小堆,各一半大小,使得最大堆始终小于等于最小堆。则根据它们的堆顶即可计算得到中位数。
注意由于python的heapq引起的语法麻烦:最大堆里面存放的是负值。
class MedianFinder:
def __init__(self):
self.small = [] # 最大堆, 存较小的元素, 存的都是负值
self.large = [] # 最小堆, 存较大的元素, 存的都是正值
def addNum(self, num: int) -> None:
# 始终使得最大堆小于等于最小堆
heapq.heappush(self.small, -num)
if self.small and self.large and -self.small[0] > self.large[0]:
val = -heapq.heappop(self.small)
heapq.heappush(self.large, val)
# 最大堆比最小堆多至多一个元素
if len(self.small) > len(self.large) + 1:
val = -heapq.heappop(self.small)
heapq.heappush(self.large, val)
elif len(self.large) > len(self.small):
val = -heapq.heappop(self.large)
heapq.heappush(self.small, val)
def findMedian(self) -> float:
if (len(self.small) + len(self.large)) % 2:
return -self.small[0]
else:
return (-self.small[0] + self.large[0]) / 2
# Your MedianFinder object will be instantiated and called as such:
# obj = MedianFinder()
# obj.addNum(num)
# param_2 = obj.findMedian()
专题14 贪心
虽然同样称为贪心,但是这一套贪心的四道题和算法导论的四道题细究起来并不是一类。
算法导论的贪心一般是“做显式的贪心选择”,通过替换/交换法进行贪心论证。例如活动选择问题,每次都选择结束时间最早的相容活动,这样的话可以给其他活动留出最多的时间、以整体选择最多的活动。
而这里的四道题更倾向于“迭代维护状态,以做出最优选择”。
第一道需要在某个价格时买入(但并不知道什么时候买入)、在当前价格时卖出,所以维护历史最低价格;
第二道需要知道最远能到达哪里,所以边遍历边维护;
第三道需要跳跃的最少次数,所以需要知道什么时候必须跳跃的边界;
第四道需要划分开当前字符串段的最少次数,所以需要知道当前字母出现的最远位置。
复杂一些,现在还想得不那么明白。慢慢品味。
121 买卖股票的最佳时机
class Solution:
def maxProfit(self, prices: List[int]) -> int:
# 当前卖出时能获得的最大利润, 应该是当前价格减去历史最低价格.
min_price = prices[0]
res = 0
for price in prices:
res = max(res, price - min_price)
min_price = min(min_price, price)
return res
55 跳跃游戏
遍历下标,维护一个当前最远可达下标。
如果最远可达下标小于当前下标,则返回False,否则最远可达下标更新。
感觉这两道题与其说是贪心,不如说是维护一个最值。
class Solution:
def canJump(self, nums: List[int]) -> bool:
maxReach = 0
for i in range(len(nums)):
if maxReach < i:
return False
maxReach = max(maxReach, i + nums[i])
if maxReach >= len(nums) - 1:
return True
return maxReach >= len(nums) - 1
45 跳跃游戏 II
写了一个不好的dp,维护从某个下标跳跃到最后一个下标的最小步数。
class Solution:
def jump(self, nums: List[int]) -> int:
minStep = [float('inf')] * len(nums)
minStep[-1] = 0
for i in range(len(nums) - 2, -1, -1):
# 对于某个下标i, 遍历它可达的所有下标, 选取其中跳跃到最后下标的最小值.
for j in range(i + 1, min(len(nums), i + nums[i] + 1)):
minStep[i] = min(minStep[i], minStep[j] + 1)
return minStep[0]
然后写了贪心。
贪心策略是,cur_end维护当前jumps数能够跳到的最远位置。
class Solution:
def jump(self, nums: List[int]) -> int:
n = len(nums)
if n == 1:
return 0
jumps = 0
cur_end = 0
farthest = 0
for i in range(n - 1):
farthest = max(farthest, i + nums[i])
if i == cur_end: # 需要多跳一次
jumps += 1
cur_end = farthest
# 注意这个剪枝不能写在farthest更新的下一行, 因为需要先更新完jump数.
if cur_end >= n - 1:
break
return jumps
763 划分字母区间
在遍历到每个字母时,更新当前字母的最远位置。如果当前位置已经达到最远位置,则划分成一段。
class Solution:
def partitionLabels(self, s: str) -> List[int]:
last_pos = {}
for i, ch in enumerate(s):
last_pos[ch] = i
res = []
start = 0
end = 0
for i, ch in enumerate(s):
end = max(end, last_pos[ch])
if i == end:
res.append(end - start + 1)
start = i + 1
return res
专题15 动态规划
动态规划的本质就是填表格查表格。
某个问题可以由一些子问题的值得到,所以查子问题的表格,然后填入该问题的表格。
70 爬楼梯
class Solution:
def climbStairs(self, n: int) -> int:
# 问题的解由子问题的解组成.
# a[n] = a[n - 1] + a[n - 2]
a = [1, 1]
for i in range(2, n + 1):
a.append(a[i - 1] + a[i - 2])
return a[n]
118 杨辉三角
class Solution:
def generate(self, numRows: int) -> List[List[int]]:
if numRows == 1:
return [[1]]
elif numRows == 2:
return [[1], [1, 1]]
else:
cur_list = [[1], [1, 1]]
for i in range(2, numRows):
cur_list.append([1] * (i + 1))
# eg. i = 3时, j从1到2
for j in range(1, i):
cur_list[i][j] = cur_list[i - 1][j - 1] + cur_list[i - 1][j]
return cur_list
198 打家劫舍
class Solution:
def rob(self, nums: List[int]) -> int:
if len(nums) == 1:
return nums[0]
dp = [0] * len(nums)
dp[0] = nums[0]
dp[1] = max(nums[0], nums[1])
for i in range(2, len(nums)):
dp[i] = max(dp[i - 2] + nums[i], dp[i - 1])
return dp[len(nums) - 1]
由于只依赖于上两个状态,因此可以只用两个变量滚动,实现空间的简化。
class Solution:
def rob(self, nums: List[int]) -> int:
if len(nums) == 1:
return nums[0]
prev2 = nums[0]
prev1 = max(nums[0], nums[1])
for i in range(2, len(nums)):
cur = max(prev2 + nums[i], prev1)
prev2 = prev1
prev1 = cur
return prev1
279 完全平方数
递推做法。
class Solution:
def numSquares(self, n: int) -> int:
dp = [float('inf')] * (n + 1)
dp[0], dp[1] = 0, 1
for i in range(2, n + 1):
for j in range(1, int(sqrt(i)) + 1):
dp[i] = min(dp[i], dp[i - j * j] + 1)
return dp[n]
以下是一个带cache的递归做法,奇慢,但是能过。
这道题递归不如递推,因为从0到n的状态一定都需要计算(每个数至少可以减1*1),没有可以剪枝的状态。
class Solution:
def numSquares(self, n: int) -> int:
if n == 0:
return 0
elif not hasattr(self, 'numCache'):
self.numCache = [float('inf')] * (n + 1)
self.numCache[0] = 0
elif hasattr(self, 'numCache') and self.numCache[n] != float('inf'):
return self.numCache[n]
minCnt = n
for i in range(1, int(sqrt(n)) + 1):
minCnt = min(minCnt, self.numSquares(n - i * i) + 1)
self.numCache[n] = minCnt
return minCnt
322 零钱兑换
先来一个不带cache的递归,当然TLE过不了。
class Solution:
def coinChange(self, coins: List[int], amount: int) -> int:
if amount < 0:
return -1
elif amount == 0:
return 0
minCnt = float('inf')
for coin in coins:
cnt = self.coinChange(coins, amount - coin)
if cnt == -1:
continue
minCnt = min(minCnt, cnt + 1)
if minCnt == float('inf'):
return -1
else:
return minCnt
接下来给这个递归加个cache就能过了,只是慢一点。
class Solution:
def coinChange(self, coins: List[int], amount: int) -> int:
if amount < 0:
return -1
elif amount == 0:
return 0
elif not hasattr(self, 'coinCache'):
self.coinCache = [float('inf')] * (amount + 1)
self.coinCache[0] = 0
elif hasattr(self, 'coinCache') and self.coinCache[amount] != float('inf'):
return self.coinCache[amount]
minCnt = float('inf')
for coin in coins:
cnt = self.coinChange(coins, amount - coin)
if cnt == -1:
continue
minCnt = min(minCnt, cnt + 1)
if minCnt == float('inf'):
self.coinCache[amount] = -1
return -1
else:
self.coinCache[amount] = minCnt
return minCnt
那么这样的递推比递归快多了。顺手加了个小剪枝。
class Solution:
def coinChange(self, coins: List[int], amount: int) -> int:
if amount == 0:
return 0
coins.sort() # 顺手排个升序, 方便continue改成break
coinCache = [float('inf')] * (amount + 1)
coinCache[0] = 0
for i in range(1, amount + 1):
for coin in coins:
if i - coin < 0:
break
coinCache[i] = min(coinCache[i], coinCache[i - coin] + 1)
if coinCache[amount] == float('inf'):
return -1
else:
return coinCache[amount]
139 单词拆分
这里转移的实体是字符串。同构的实体是结尾到下标i的字符串段,我们要看的是同构实体是否可以拆分。
那么对于某个特定的同构实体,我们只需要遍历它所有可能的拆分点、看是否有拆分点前半部分是同构实体,后半部分在字典中即可。
class Solution:
def wordBreak(self, s: str, wordDict: List[str]) -> bool:
# 对于字符串的dp, 要意识到字符串一般都是从左往右遍历下标.
# 那么对于结尾为i(开)的字符串s[0..i],可以分割意味着存在分割点j, 使得dp[j]=True且s[j..i]在wordDict中.
wordDict = set(wordDict) # 会快很多
n = len(s)
dp = [False] * (n + 1)
dp[0] = True # 空串
for i in range(n + 1):
for j in range(i):
if dp[j] and s[j:i] in wordDict:
dp[i] = True
return dp[n]
总之dp可以念这样一句话:
“对于特定同构实体,它可以由哪些同构实体转移得到”。
152 乘积最大子数组
到i的乘积最大值,可能由最大值、最小值或不选,三种情况转移得到。容易漏解。
class Solution:
def maxProduct(self, nums: List[int]) -> int:
# 到i的乘积最大值, 可能由**最大值或最小值**转移得到.
res = nums[0]
prev_max = prev_min = nums[0]
for i in range(1, len(nums)):
curr_max = max(nums[i], prev_max * nums[i], prev_min * nums[i])
curr_min = min(nums[i], prev_max * nums[i], prev_min * nums[i])
res = max(res, curr_max)
prev_max, prev_min = curr_max, curr_min
return res
416 分割等和子集
将分割等和子集,转化成在集合中选取一些元素,使得它们的和恰好等于总和的二分之一。这样的约束问题恰好是0-1背包的变种,可以设置dp为“前i个元素是否能够得到和为j”。
class Solution:
def canPartition(self, nums: List[int]) -> bool:
total = sum(nums)
if total % 2:
return False
target = total // 2
n = len(nums)
# 前i个元素和为target
dp = [[False] * (target + 1) for _ in range(n + 1)]
for i in range(n + 1):
dp[i][0] = True
for i in range(1, n + 1):
# 这里前i个元素, 实际要添加的元素是nums[i - 1]
for j in range(1, target + 1):
if j < nums[i - 1]:
dp[i][j] = dp[i - 1][j]
else:
dp[i][j] = dp[i - 1][j] or dp[i - 1][j - nums[i - 1]]
return dp[n][target]
之后因为每一行的表格都只依赖于上一行的表格,再使用类似的二维背包转一维背包的空间优化,去掉行下标,然后列下标的遍历一定只能倒着来。
这个一维dp空间优化本质是因为,j - num使用的是“上一行”的状态(前i个由前i-1个决定),从大到小遍历j的话可以保证这样填入每处dp时使用的都是“上一行”的状态。
而如果从小到大遍历,则j - num可能已经被更新为了“新一行”的状态,而“同一行”的状态互相转移(前i个由前i个决定)是混乱且不允许的。
最后再整体审视一下这个背包。其实时间复杂度是完全没有变的,转移关系也是完全没有变的。外层仍然需要遍历所有“前i个”,只是内层为了配合空间上的优化,所用的遍历顺序发生了变化。
想清楚了的话,下面两句话不言自明:
- 二维01背包,内层循环正着倒着遍历都行。
- 优化为一维01背包后,内层循环只能倒着遍历。
class Solution:
def canPartition(self, nums: List[int]) -> bool:
total = sum(nums)
if total % 2:
return False
target = total // 2
# dp[j] 表示能否选出和为 j 的子集
dp = [False] * (target + 1)
dp[0] = True # 和为0总是可以
for num in nums:
# 必须从大到小遍历,避免重复使用同一个数
for j in range(target, num - 1, -1):
if dp[j - num]:
dp[j] = True
# 提前结束
if dp[target]:
return True
return dp[target]
32 最长有效括号
栈解法存入所有左括号的坐标。
每当遇到右括号时,将它与左括号匹配,根据栈顶指示的位置更新最大长度跨度。否则如果是孤立右括号,作为哨兵填入。
这里的stk初值取-1是应对 '()' 这样的情况,在弹出时返回值应为2、此时i=1,所以初值应取-1。(栈顶值应为最长匹配括号的前一个位置)
class Solution:
def longestValidParentheses(self, s: str) -> int:
stk = [-1]
maxlen = 0
for i, ch in enumerate(s):
if ch == '(':
stk.append(i)
else:
stk.pop()
if not stk: # stk已为空
stk.append(i)
else:
maxlen = max(maxlen, i - stk[-1])
return maxlen
专题16 多维动态规划
62 不同路径
完全模拟了题目要求的形状。注意一下从右下往左上转移的顺序就行。
class Solution:
def uniquePaths(self, m: int, n: int) -> int:
dp = [[0] * n for _ in range(m)]
for j in range(n):
dp[m - 1][j] = 1
for i in range(m):
dp[i][n - 1] = 1
for i in range(m - 2, -1, -1):
for j in range(n - 2, -1, -1):
dp[i][j] = dp[i + 1][j] + dp[i][j + 1]
return dp[0][0]
64 最小路径和
class Solution:
def minPathSum(self, grid: List[List[int]]) -> int:
m, n = len(grid), len(grid[0])
dp = [[float('inf')] * n for _ in range(m)]
dp[m - 1][n - 1] = grid[m - 1][n - 1]
for i in range(m - 2, -1, -1):
dp[i][n - 1] = dp[i + 1][n - 1] + grid[i][n - 1]
for j in range(n - 2, -1, -1):
dp[m - 1][j] = dp[m - 1][j + 1] + grid[m - 1][j]
for i in range(m - 2, -1, -1):
for j in range(n - 2, -1, -1):
# 下面右面二选一
dp[i][j] = min(dp[i + 1][j], dp[i][j + 1]) + grid[i][j]
return dp[0][0]
5 最长回文子串
很干净的子串遍历和自底向下填表格问题,值得记忆。
记得像Dijkstra说的那样,左闭右开。
顺手推一下循环上界:
(1) 我们使用的字符子串是 s[i:i+length],所以有 i + length <= n 得到内层 i < n - length + 1。
(2) 最大的子串应为 s[0:n],此时i = 0,length = n,所以有外层 length < n + 1。
class Solution:
def longestPalindrome(self, s: str) -> str:
n = len(s)
if n == 1:
return s
# dp[i][j]表示s[i:j+1]是否回文
dp = [[False] * n for _ in range(n)]
start = 0 # 用于返回解
maxlen = 1
for i in range(n):
dp[i][i] = True
# 字符串是s[i:i+length]
# 字符串最后一个字符是s[i + length - 1]
for length in range(2, n + 1):
for i in range(n - length + 1):
j = i + length - 1
if s[i] == s[j]:
if length == 2:
dp[i][j] = True
else:
dp[i][j] = dp[i+1][j-1]
if dp[i][j] and length > maxlen:
maxlen = length
start = i
return s[start:start + maxlen]
1143 最长公共子序列
皮一下,内层只写一行。
除了转移逻辑,记得处理一下边界。这里字符串下标使用实际下标,但dp使用下标+1,处理边界。
class Solution:
def longestCommonSubsequence(self, text1: str, text2: str) -> int:
# i是s1的结束位置, j是s2的结束位置
m, n = len(text1), len(text2)
dp = [[0] * (n + 1) for _ in range(m + 1)]
for i in range(1, m + 1):
for j in range(1, n + 1):
dp[i][j] = dp[i - 1][j - 1] + 1 if text1[i - 1] == text2[j - 1] else max(dp[i - 1][j], dp[i][j - 1])
return dp[m][n]
72 编辑距离
不要被题目吓到。其实就是最长公共子序列那种感觉。题目的三种方式只是三种转移。
class Solution:
def minDistance(self, word1: str, word2: str) -> int:
m, n = len(word1), len(word2)
# 将word1[0:i]转化为word2[0:j]的最少操作数
dp = [[0] * (n + 1) for _ in range(m + 1)]
for i in range(m + 1):
dp[i][0] = i
for j in range(n + 1):
dp[0][j] = j
for i in range(1, m + 1):
for j in range(1, n + 1):
if word1[i - 1] == word2[j - 1]:
dp[i][j] = dp[i - 1][j - 1]
else:
dp[i][j] = min(dp[i - 1][j - 1], dp[i - 1][j], dp[i][j - 1]) + 1
return dp[m][n]
专题17 技巧
136 只出现一次的数字
把出现偶数次的用异或消除掉。
class Solution:
def singleNumber(self, nums: List[int]) -> int:
res = 0
for num in nums:
res ^= num
return res
169 多数元素
寻找众数的方法。通过投票,赞同当前提议则投正面票,反对当前提议则投负面票,最后留下的就是众数。
class Solution:
def majorityElement(self, nums: List[int]) -> int:
count = 0
majority = -1
for num in nums:
if count == 0:
majority = num
count += 1
elif majority == num:
count += 1
else:
count -= 1
return majority
75 颜色分类
其实是中间指针用于扫描,把元素分配到左边指针和右边指针的动态空间的过程。
关于cur指针是否移动,左右指针有所区别:
如果交换到l指针,
一开始:它们都是0,则交换后cur指向的元素(同时也是l指向的元素)位置已完成处理,cur可以移动。
过程中:l指针指向判断过的元素,cur与它交换后两个指针都是处理过的元素,cur可以移动。
如果交换到r指针,
一开始:r指针指向的未处理,cur指针与它交换后,r指针指向的已处理,但是cur指针指向的元素没有处理。所以cur不移动。
class Solution:
def sortColors(self, nums: List[int]) -> None:
"""
Do not return anything, modify nums in-place instead.
"""
# l和r是待分配位置, cur是正在扫描的元素
l, cur, r = 0, 0, len(nums) - 1
while cur <= r:
if nums[cur] == 0:
nums[cur], nums[l] = nums[l], nums[cur]
l += 1
cur += 1
elif nums[cur] == 2:
nums[cur], nums[r] = nums[r], nums[cur]
r -= 1
# 注意!!这里cur不增加, 因为交换过来的数还没处理
else:
cur += 1
31 下一个排列
三步走:定位升序对,找最小元素,交换并翻转。
定位升序对 (nums[i], nums[i + 1]),
在 i 右侧找大于 nums[i] 的最小元素,
交换 nums[i] 和最小元素后把 i右侧翻转。
class Solution:
def reverseNums(self, nums, i, j):
while i < j:
nums[i], nums[j] = nums[j], nums[i]
i += 1
j -= 1
def nextPermutation(self, nums: List[int]) -> None:
"""
Do not return anything, modify nums in-place instead.
"""
# [1,2,3] [1,3,2] [2,1,3] [2,3,1] [3,1,2] [3,2,1]
# 定位从右往左第一个升序对 (nums[i], nums[i + 1]),
# 在nums[i+1:]中取大于nums[i]的最小值, 将最小值与nums[i]交换.
# 然后翻转nums[i+1:].
n = len(nums)
exist = False
for i in range(n - 2, -1, -1):
# 定位升序对
if nums[i] < nums[i + 1]:
exist = True
# 在i右边找最小元素作为待交换的元素, 注意有重复时应选择右边的
min_j = i + 1
for j in range(i + 2, n):
if nums[i] < nums[j] <= nums[min_j]:
min_j = j
# 交换, 然后把i右边翻转
nums[i], nums[min_j] = nums[min_j], nums[i]
self.reverseNums(nums, i + 1, len(nums) - 1)
break
if not exist:
self.reverseNums(nums, 0, len(nums) - 1)
287 寻找重复数
利用二分进行值域查找。重复数位于的区间性质是“个数比元素值大”。
class Solution:
def findDuplicate(self, nums: List[int]) -> int:
# eg. [1, 2, 2, 3, 4]
# 如果某个值(如3), 小于等于它的个数比这个数本身要大, 则重复数位于这一段.
l, r = 1, len(nums) - 1
while l < r:
mid = (l + r) // 2
# 计数小于等于它的个数
cnt = 0
for num in nums:
if num <= mid:
cnt += 1
# 重复数是否位于左半段
if cnt > mid:
r = mid
else:
l = mid + 1
return l