从SGD到AdamW,优化器怎么发展过来的?
Adam = Momentum + RMSProp
本部分是自己对AdamW优化器的初步学习和理解,代码均为DeepSeek v3.2生成,相比于PyTorch的工程完整实现做了简化,注重核心内容。
有一点自己不满意的是,觉得对AdaGrad的笔记写得不好。在有更进一步的了解时希望把这一部分修改一下。
edit time: 2026-03-11 21:34:12
本文可以省流成以下几句话:
SGD往梯度下降的方向更新权重。
SGD+Momentum把梯度累积起来、得到了方向,一直同向就更新快一点,变向就慢一点。
AdaGrad把梯度的平方累积起来,让出现得频繁却梯度值很小的步长更大。
RMSProp给AdaGrad加了一个衰减系数,不看整个历史、只看近期历史,防止学习率消失。
Adam = Momentum + RMSProp。
AdamW解决了在使用Adam时应该怎么做权重衰减。
| 算法 | 动量 | 自适应LR | 权重衰减 | 关键创新 |
|---|---|---|---|---|
| SGD | ❌ | ❌ | ❌ | 基础 |
| SGD+Momentum | ✅ | ❌ | ❌ | 加速收敛 |
| AdaGrad | ❌ | ✅ | ❌ | 自适应学习率 |
| RMSProp | ❌ | ✅ | ❌ | 指数移动平均 |
| Adam | ✅ | ✅ | ❌ | Momentum + RMSProp |
| AdamW | ✅ | ✅ | ✅(解耦) | 正确权重衰减 |
SGD
是理论上最基础的梯度下降,沿着梯度的反方向更新参数。
class SGD:
def __init__(self, lr=0.01):
self.lr = lr
def step(self, params, grads):
for param, grad in zip(params, grads):
param -= self.lr * grad # 最简单的梯度下降
SGD with Momentum
动量梯度下降,引入“速度”的概念,用于累积历史梯度方向(称为一阶方法)。
现在参数的更新值不再是步长乘负梯度,而是速度。速度累积了历史的梯度变化量。
“如果梯度方向持续相同就加速,梯度方向反转就减速”,
很像一个小球滚下来的过程。
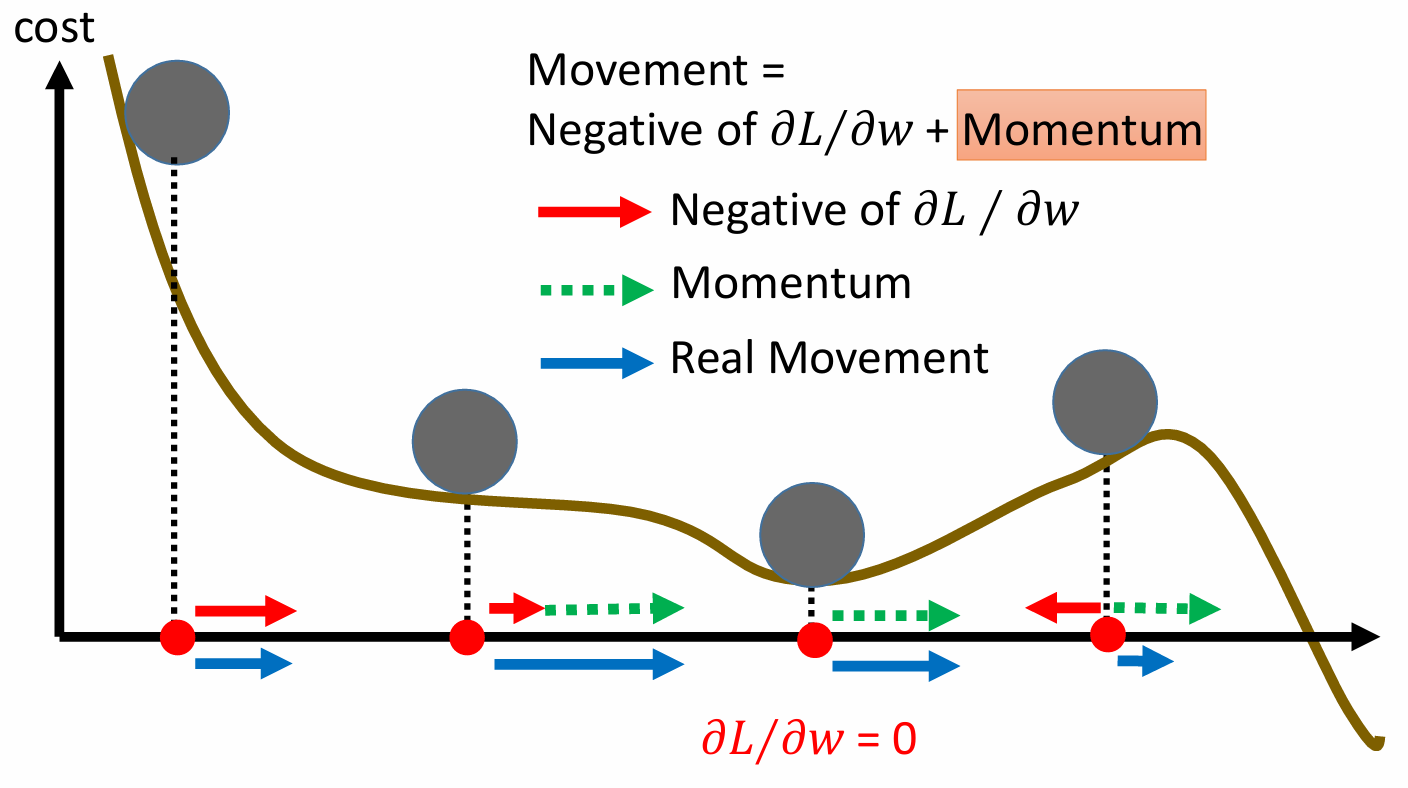
(图片来自 李宏毅机器学习 Part IV: Tips for Training DNN )
class SGDMomentum:
def __init__(self, lr=0.01, momentum=0.9):
self.lr = lr
self.momentum = momentum # 动量系数 γ
self.v = {} # 速度
def step(self, params, grads):
for i, (param, grad) in enumerate(zip(params, grads)):
if i not in self.v:
self.v[i] = 0
# 更新速度(动量)
self.v[i] = self.momentum * self.v[i] - self.lr * grad
# 更新参数
param += self.v[i]
AdaGrad
自适应学习率,关注历史梯度大小。
它考虑到不同特征出现的频率不同,高频特征可能过度训练、低频特征可能欠拟合。所以根据特征出现的频率,自适应调整学习率,让低频特征学习率更高。
“梯度出现频繁的,学习率更高”。
那么为什么使用平方呢?因为我们需要用到梯度的绝对数值,但直接累积会出现方向的抵消。
class AdaGrad:
def __init__(self, lr=0.01, eps=1e-8):
self.lr = lr
self.eps = eps
self.cache = {} # 梯度平方累积
def step(self, params, grads):
for i, (param, grad) in enumerate(zip(params, grads)):
if i not in self.cache:
self.cache[i] = 0
# 累积梯度平方
self.cache[i] += grad ** 2
# 自适应学习率更新
param -= self.lr * grad / (self.cache[i] ** 0.5 + self.eps)
注意,这里步长考虑的是梯度出现频繁。
对于出现频繁,比如下述例子考虑某一步的情况,此时0.01的梯度已经出现过100次、而1.0的梯度出现过1次。下述计算发现前者此时的有效学习率大于后者(1.0 > 0.1)。
# 场景1:梯度数值小但出现频繁
grads_frequent_small = [0.01] * 100 # 100次,每次都0.01
cache_frequent = sum([g**2 for g in grads_frequent_small]) # = 100 * 0.0001 = 0.01
delta_frequent = 0.1 / np.sqrt(cache_frequent) # 0.1 / 0.1 = 1.0
# 场景2:梯度数值大但出现稀疏
grads_sparse_big = [1.0] * 1 # 只出现1次,但数值1.0
cache_sparse = sum([g**2 for g in grads_sparse_big]) # = 1 * 1.0 = 1.0
delta_sparse = 0.1 / np.sqrt(cache_sparse) # 0.1 / 1.0 = 0.1
感觉讲得还是不太好。如果之后有更进一步的理解了,这里可以更新一下。
RMSProp
AdaGrad随着梯度平方的累积,学习率会递减到0,出现学习率消失问题。
RMSProp在AdaGrad的基础上加入了衰减(称为“指数移动平均/EMA”),使得它看的历史从无限长变成了近期历史,解决了学习率消失问题,对学习率的适应更好。
class RMSProp:
def __init__(self, lr=0.001, decay=0.9, eps=1e-8):
self.lr = lr
self.decay = decay # 衰减率
self.eps = eps
self.cache = {}
def step(self, params, grads):
for i, (param, grad) in enumerate(zip(params, grads)):
if i not in self.cache:
self.cache[i] = 0
# 指数移动平均累积梯度平方
self.cache[i] = self.decay * self.cache[i] + (1 - self.decay) * grad ** 2
# 更新参数
param -= self.lr * grad / (self.cache[i] ** 0.5 + self.eps)
Adam
Adam = Momentum + RMSProp。
相当于既要累积历史梯度方向(一阶, ),又要累积历史梯度大小(二阶, )。
以下是对上述形式的一些数学推导证明:为什么是这样的衰减形式、以及修正系数的引入。
但是,我们希望追问一下:RMSProp那个“指数移动平均”(加了个衰减系数)到底是什么?
联系一下概率论的“矩估计”知识,结论是:指数移动平均是对期望的在线估计。也就是说,我们上面实际上是把梯度平方的累积值,换成了梯度平方的期望。
下述证明一下。我们要找到估计 和值 的关系。
递归代入展开:
令 ,则有估计值的公式为:
这个形式是对 的加权平均(所以才叫指数移动平均嘛)。权重是如下 。(ps. 容易证明,权重总和为 。)
接下来取这个估计值的期望:
\begin{align} E[\hat{\mu}_t] &= E\left[ (1-\beta) \sum_{i=1}^t \beta^{t-i} x_i \right] \\ &= (1-\beta) \sum_{i=1}^t \beta^{t-i} E[x_i] \\ &= (1-\beta) \mu \sum_{i=1}^t \beta^{t-i} \\ &= \mu (1-\beta^t) \end{align}
所以我们发现,对估计值 除以一个偏差系数 ,就可以得到对期望 (其实这个式子不是显然的,而是基于局部近似平稳的假设)的无偏估计。
因此,我们一开始的结论得证:
class Adam:
def __init__(self, lr=0.001, betas=(0.9, 0.999), eps=1e-8):
self.lr = lr
self.beta1, self.beta2 = betas
self.eps = eps
self.m = {} # 一阶矩(动量)
self.v = {} # 二阶矩(自适应)
self.t = 0 # 时间步
def step(self, params, grads):
self.t += 1
for i, (param, grad) in enumerate(zip(params, grads)):
if i not in self.m:
self.m[i] = 0
self.v[i] = 0
# 更新矩估计
self.m[i] = self.beta1 * self.m[i] + (1 - self.beta1) * grad
self.v[i] = self.beta2 * self.v[i] + (1 - self.beta2) * grad ** 2
# 偏差修正
m_hat = self.m[i] / (1 - self.beta1 ** self.t)
v_hat = self.v[i] / (1 - self.beta2 ** self.t)
# Adam更新
param -= self.lr * m_hat / (v_hat ** 0.5 + self.eps)
AdamW
Adam本身很好了,就是加上权重衰减时,容易用错。
对比以下Adam和AdamW的关键实现区别,发现AdamW把权重衰减和梯度更新分开了。
原来Adam是先对梯度做权重衰减、然后用衰减后的值做梯度更新;
现在AdamW直接用原始梯度值做梯度更新、然后对更新结果做权重衰减。
省流一下,就是把权重衰减挪到了整个step的最后面单独做。
不然的话,Adam的权重衰减(正则化)效果其实是被自适应学习率影响了的,这样的话才真正地同时实现了Adam和权重衰减两个目的的原始含义。
# Adam
# 第1步:在梯度上加L2正则化
grad = grad + weight_decay * param # g' = g + λθ
# 第2步:用修改后的梯度更新矩估计
exp_avg = beta1 * exp_avg + (1-beta1) * grad # m = β₁m + (1-β₁)(g+λθ)
exp_avg_sq = beta2 * exp_avg_sq + (1-beta2) * grad**2 # v = β₂v + (1-β₂)(g+λθ)²
# 第3步:Adam更新
param -= lr * m_hat / (sqrt(v_hat) + eps) # 更新步长包含了λθ的影响
# AdamW
# 第1步:更新矩估计(用原始梯度)
exp_avg = beta1 * exp_avg + (1-beta1) * grad # m = β₁m + (1-β₁)g
exp_avg_sq = beta2 * exp_avg_sq + (1-beta2) * grad**2 # v = β₂v + (1-β₂)g²
# 第2步:Adam更新(用原始梯度)
param -= lr * m_hat / (sqrt(v_hat) + eps) # θ' = θ - η·m̂/√v̂
# 第3步:单独进行权重衰减
param -= lr * weight_decay * param # θ = θ' - ηλθ
终于得到了最终的完整代码。完结撒花!
class AdamW(torch.optim.Optimizer):
def __init__(self, params, lr=1e-3, betas=(0.9, 0.999), eps=1e-8, weight_decay=0.01):
defaults = dict(lr=lr, betas=betas, eps=eps, weight_decay=weight_decay)
super().__init__(params, defaults)
def step(self, closure=None):
loss = None
if closure is not None:
loss = closure()
for group in self.param_groups:
beta1, beta2 = group['betas']
lr = group['lr']
eps = group['eps']
weight_decay = group['weight_decay']
for p in group['params']:
if p.grad is None:
continue
grad = p.grad.data
# 初始化状态
state = self.state[p]
if len(state) == 0:
state['step'] = 0
state['m'] = torch.zeros_like(p.data) # 一阶矩
state['v'] = torch.zeros_like(p.data) # 二阶矩
# 更新步数
state['step'] += 1
t = state['step']
# 更新矩估计
state['m'].mul_(beta1).add_(grad, alpha=1 - beta1)
state['v'].mul_(beta2).addcmul_(grad, grad, value=1 - beta2)
# 偏差修正
bias_correction1 = 1 - beta1 ** t
bias_correction2 = 1 - beta2 ** t
# Adam更新
denom = state['v'].sqrt().add_(eps)
step_size = lr * (bias_correction2 ** 0.5) / bias_correction1
p.data.addcdiv_(state['m'], denom, value=-step_size)
# 权重衰减(解耦)
if weight_decay != 0:
p.data.add_(p.data, alpha=-lr * weight_decay)
return loss