WanDB基础使用教程总结
WanDB是一个python库/日志托管平台,帮我们详细记录并整理了训练过程中的各种参数和指标变化,
省去了需要自己详细记录日志、绘制图表的麻烦,并且可以做超参数搜索等进阶用法。
感谢DeepSeek v3.2提供了所有的代码使用例。
edit time: 2026-03-09 13:48:37
整合入训练循环的最小模板:
import wandb
# 初始化
wandb.init(project="my-project", config={
"param1": 0.1,
"param2": 100,
})
# 训练循环
for epoch in range(10):
# 您的训练代码...
# 记录指标
wandb.log({
"loss": 0.5,
"accuracy": 0.8,
})
wandb.finish()
总结
在W&B quickstart中提到了两款产品,我们主要使用的是前者,用于记录acc、loss、运行环境和模型权重等日志信息,并且便于做简单的绘图。
基础使用:记录acc和loss的变化
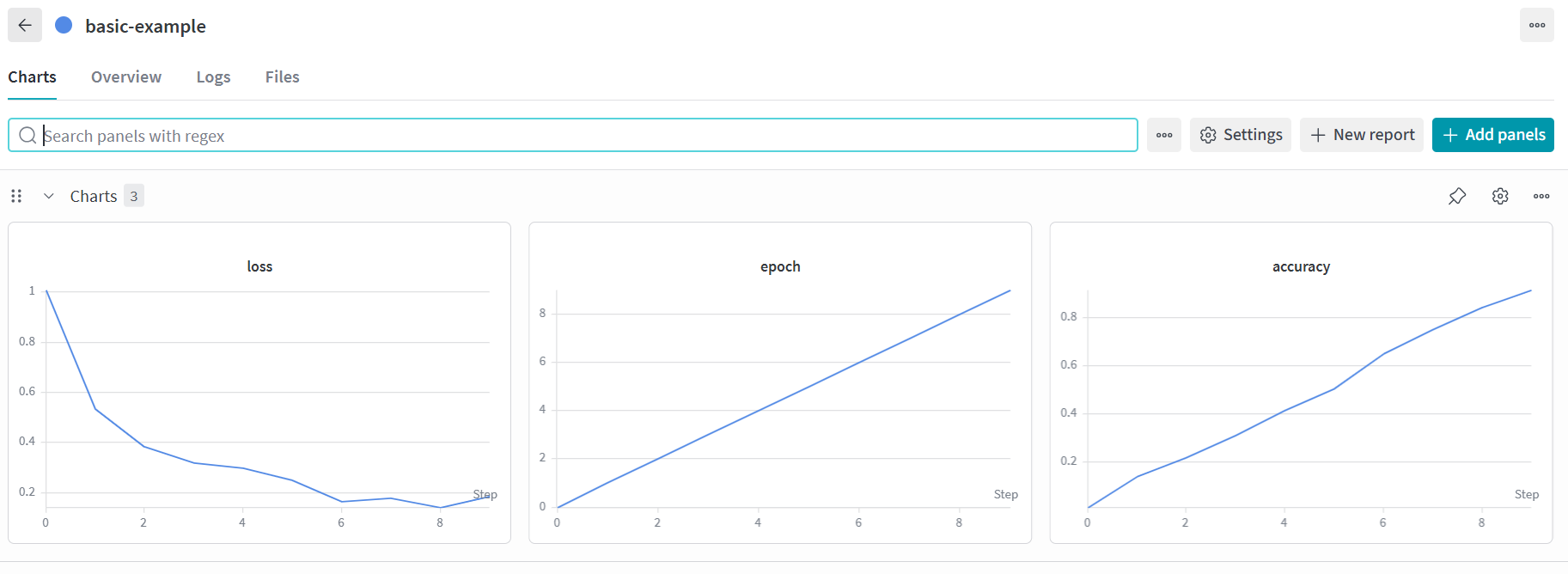
wanDB最本源的使用方式是通过 wandb.log 函数,记录 epoch, accuracy 和 loss ,只要在相关的地方把变量传给它就行。
生成一些数字看看它的效果:
import wandb
import random
import time
# 1. 初始化一个新的run
wandb.init(project="colab-demo", name="basic-example")
# 2. 模拟训练过程
for epoch in range(10):
# 模拟一些指标
loss = 1 / (epoch + 1) + random.random() * 0.1
accuracy = epoch / 10 + random.random() * 0.05
# 3. 记录指标
wandb.log({
"epoch": epoch,
"loss": loss,
"accuracy": accuracy
})
time.sleep(1) # 模拟训练时间
# 4. 结束run
wandb.finish()
print("实验完成!请查看wandb仪表板")
发现它帮我在终端生成了直观的变化图和总结。

当然这两个就是最核心的内容。但在网页上,我看到了折线图,还看到了完全固定下来的 requirements.txt 等信息,充分地表现了日志的强大之处:复现一次实验所需的所有信息。
基础使用:记录超参数config
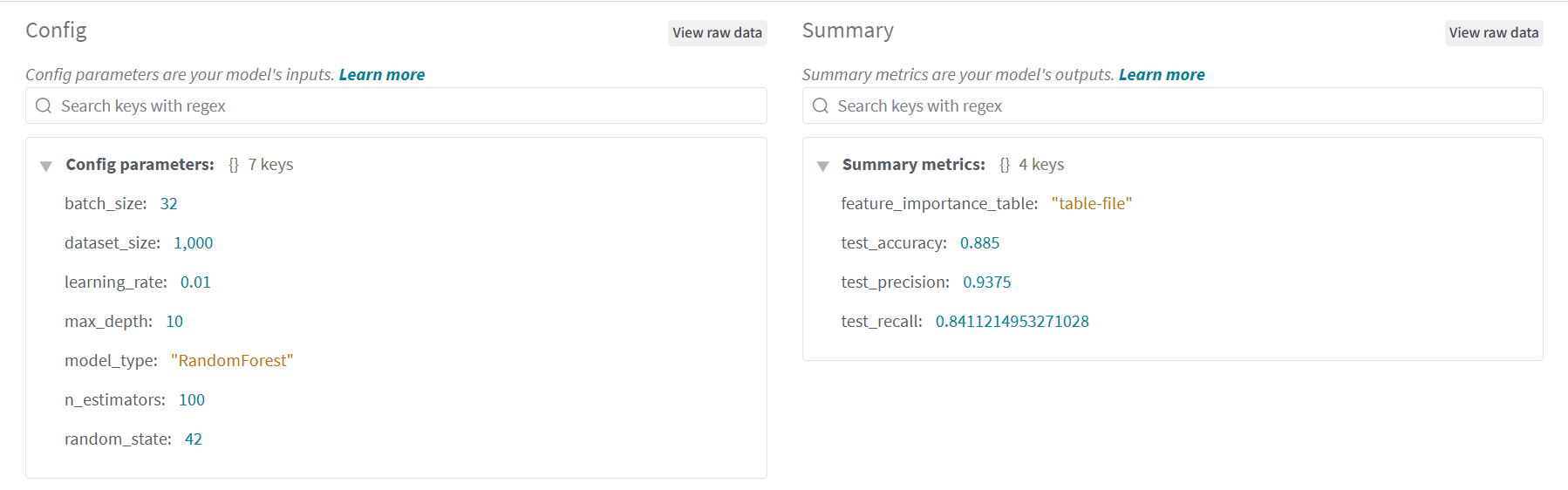
我们想记录更多的东西!那就记录吧!
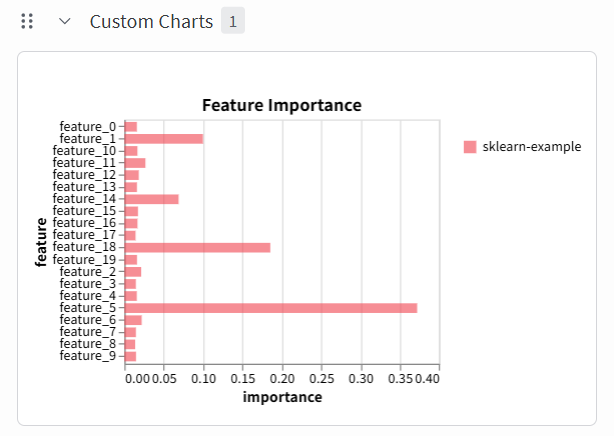
这一次还记录了 config 。 用sklearn跑了一个随机森林,看看特征的相对重要性。
import wandb
import numpy as np
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, precision_score, recall_score
# 初始化wandb并记录配置
wandb.init(
project="colab-demo",
name="sklearn-example",
config={
"learning_rate": 0.01,
"batch_size": 32,
"n_estimators": 100,
"max_depth": 10,
"random_state": 42,
"dataset_size": 1000,
"model_type": "RandomForest"
}
)
# 获取配置
config = wandb.config
# 生成示例数据
X, y = make_classification(
n_samples=config.dataset_size,
n_features=20,
random_state=config.random_state
)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=config.random_state
)
# 训练模型
model = RandomForestClassifier(
n_estimators=config.n_estimators,
max_depth=config.max_depth,
random_state=config.random_state
)
model.fit(X_train, y_train)
# 预测和评估
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
precision = precision_score(y_test, y_pred)
recall = recall_score(y_test, y_pred)
# 记录最终的指标
wandb.log({
"test_accuracy": accuracy,
"test_precision": precision,
"test_recall": recall,
"feature_importance": wandb.plot.bar(
wandb.Table(
data=[[f"feature_{i}", imp] for i, imp in enumerate(model.feature_importances_)],
columns=["feature", "importance"]
),
"feature", "importance",
title="Feature Importance"
)
})
wandb.finish()
注意以下这个图表完全是借助 wandb 提供的接口绘制的。
基础使用:PyTorch和Huggingface Transformers的集成
都一样,把变量传进去就行。某个指标、某个结果,甚至是模型权重文件 model.pth 。
但wandb的免费似乎只支持200GB的存储,需要注意。
Huggingface Transformers甚至还要更加省事:
连那些参数都不需要自己传了, Trainer 已经封装好了,只要 report_to="wandb" 就可以了。
import wandb
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset
import numpy as np
# 初始化wandb
wandb.init(
project="colab-demo",
name="pytorch-example",
config={
"learning_rate": 0.01,
"batch_size": 32,
"epochs": 20,
"hidden_size": 128,
"optimizer": "Adam"
}
)
config = wandb.config
# 生成简单的回归数据
X = torch.randn(1000, 10)
y = torch.randn(1000, 1) * 2 + 3 + torch.randn(1000, 1) * 0.1
dataset = TensorDataset(X, y)
dataloader = DataLoader(dataset, batch_size=config.batch_size, shuffle=True)
# 定义简单的神经网络
class SimpleNN(nn.Module):
def __init__(self, input_size=10, hidden_size=128, output_size=1):
super().__init__()
self.layer1 = nn.Linear(input_size, hidden_size)
self.layer2 = nn.Linear(hidden_size, hidden_size)
self.layer3 = nn.Linear(hidden_size, output_size)
self.relu = nn.ReLU()
def forward(self, x):
x = self.relu(self.layer1(x))
x = self.relu(self.layer2(x))
x = self.layer3(x)
return x
model = SimpleNN(hidden_size=config.hidden_size)
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=config.learning_rate)
# 训练循环
for epoch in range(config.epochs):
total_loss = 0
for batch_x, batch_y in dataloader:
optimizer.zero_grad()
outputs = model(batch_x)
loss = criterion(outputs, batch_y)
loss.backward()
optimizer.step()
total_loss += loss.item()
avg_loss = total_loss / len(dataloader)
# 记录训练损失
wandb.log({
"epoch": epoch,
"train_loss": avg_loss,
"learning_rate": optimizer.param_groups[0]['lr']
})
# 可选:记录模型梯度直方图
if epoch % 5 == 0:
wandb.log({
"gradients": wandb.Histogram(
torch.cat([p.grad.view(-1) for p in model.parameters() if p.grad is not None])
)
})
print(f"Epoch {epoch+1}/{config.epochs}, Loss: {avg_loss:.4f}")
# 保存模型
torch.save(model.state_dict(), "model.pth")
wandb.save("model.pth") # 将模型文件保存到wandb
wandb.finish()
import wandb
from transformers import (
AutoTokenizer,
AutoModelForSequenceClassification,
TrainingArguments,
Trainer
)
from datasets import load_dataset
import numpy as np
from sklearn.metrics import accuracy_score
# 1. 初始化wandb(这里可以指定项目名和实验名)
wandb.init(project="huggingface-colab-demo", name="automatic-logging-run")
# 2. 准备数据
dataset = load_dataset("imdb", split="train[:100]") # 只取100条,让实验更快
tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased")
def tokenize_function(examples):
return tokenizer(examples["text"], padding="max_length", truncation=True, max_length=128)
tokenized_dataset = dataset.map(tokenize_function, batched=True)
# 3. 加载模型
model = AutoModelForSequenceClassification.from_pretrained("distilbert-base-uncased", num_labels=2)
# 4. 配置TrainingArguments,关键就是 report_to="wandb"
training_args = TrainingArguments(
output_dir="./results",
num_train_epochs=2,
per_device_train_batch_size=8,
logging_steps=10, # 每10步记录一次日志
report_to="wandb", # 👈 告诉Trainer用wandb记录
run_name="bert-imdb-quick-test", # 这次运行的名字
)
# 5. 定义评估指标
def compute_metrics(eval_pred):
predictions, labels = eval_pred
predictions = np.argmax(predictions, axis=1)
return {"accuracy": accuracy_score(labels, predictions)}
# 6. 创建Trainer并开始训练
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_dataset,
eval_dataset=tokenized_dataset, # 简单起见,用训练集评估
compute_metrics=compute_metrics,
)
trainer.train()
# 7. 结束实验
wandb.finish()
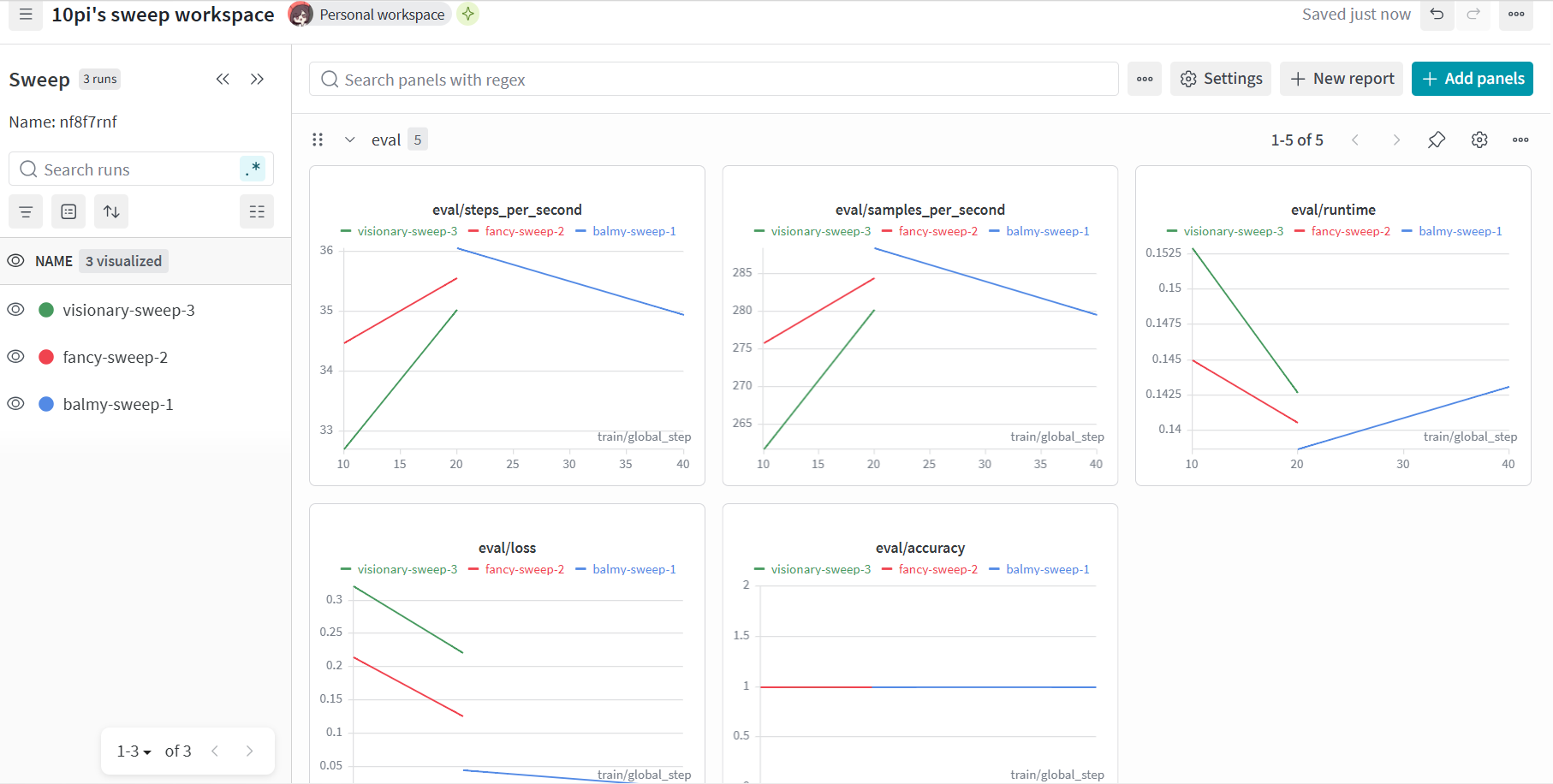
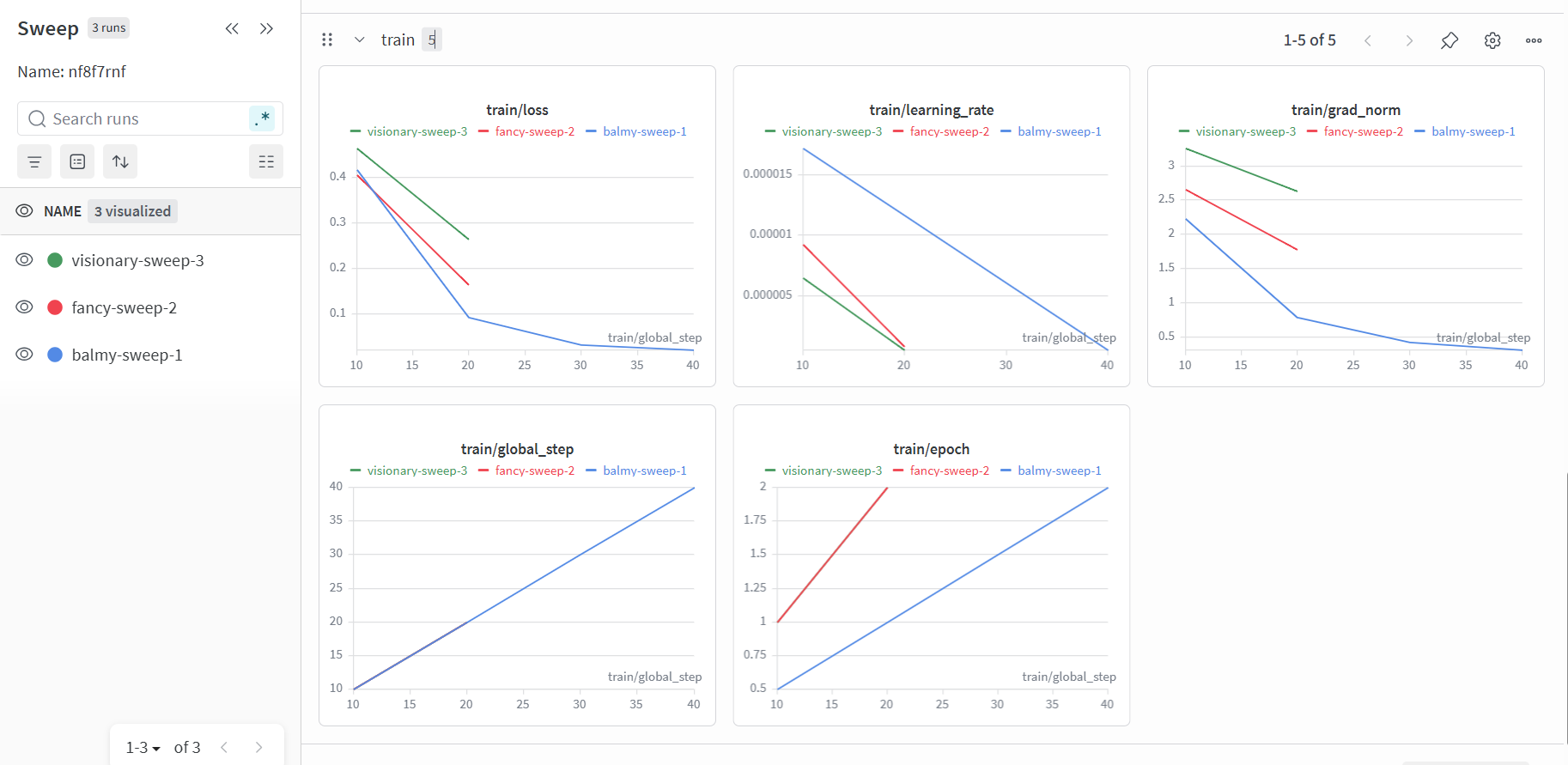
进阶使用:超参数搜索
定义搜索空间后,wandb可用于超参数搜索。
例如下述定义了 learning_rate 在 [1e-5, 1e-4] 之间,服从对数均匀分布。
对数均匀分布意味着在数量级上均匀采样。比如从1e-5到1e-4,虽然数值看起来“偏向”小值,但在对数尺度上是均匀的——这正好适合学习率这种需要跨数量级尝试的参数。
之后我利用for循环串行运行了三次,wandb帮我测试的 lr 分别为 2.213804440450783e-05 ,1.6808858635707506e-05 ,1.1746289104917436e-05 。
还定义了 per_device_train_batch_size 为 8 或 16 ,实际跑了一次 8 、两次 16 。
import wandb
from transformers import (
AutoTokenizer,
AutoModelForSequenceClassification,
TrainingArguments,
Trainer
)
from datasets import load_dataset
import numpy as np
from sklearn.metrics import accuracy_score
import time
import random
# 设置随机种子避免冲突
random.seed(int(time.time()))
sweep_config = {
"method": "random",
"metric": {"name": "eval_accuracy", "goal": "maximize"},
"parameters": {
"learning_rate": {
"distribution": "log_uniform_values",
"min": 1e-5,
"max": 1e-4
},
"per_device_train_batch_size": {"values": [8, 16]},
"num_train_epochs": {"values": [2]}
}
}
def train():
# 每个run完全独立初始化
run = wandb.init(project="huggingface-colab-demo", reinit=True)
config = wandb.config
try:
print(f"开始训练 {run.id}")
# 数据准备
dataset = load_dataset("imdb", split="train[:200]")
tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased")
def tokenize_function(examples):
return tokenizer(examples["text"], padding="max_length", truncation=True, max_length=128)
tokenized_dataset = dataset.map(tokenize_function, batched=True)
train_valid_split = tokenized_dataset.train_test_split(test_size=0.2, seed=42)
model = AutoModelForSequenceClassification.from_pretrained(
"distilbert-base-uncased",
num_labels=2
)
training_args = TrainingArguments(
output_dir=f"./results/sweep_{run.id}",
num_train_epochs=config.num_train_epochs,
per_device_train_batch_size=config.per_device_train_batch_size,
learning_rate=config.learning_rate,
logging_steps=10,
eval_strategy="epoch",
save_strategy="no",
report_to="wandb",
run_name=f"sweep-{run.id}",
)
def compute_metrics(eval_pred):
predictions, labels = eval_pred
predictions = np.argmax(predictions, axis=1)
return {"accuracy": accuracy_score(labels, predictions)}
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_valid_split["train"],
eval_dataset=train_valid_split["test"],
compute_metrics=compute_metrics,
)
trainer.train()
except Exception as e:
print(f"错误: {e}")
wandb.log({"error": str(e)})
finally:
wandb.finish()
# 强制等待一小段时间,避免资源竞争
time.sleep(2)
# 创建sweep
sweep_id = wandb.sweep(sweep_config, project="huggingface-colab-demo")
# 串行运行,每次只跑一个
for i in range(3): # 跑3次
print(f"\n=== 开始第 {i+1}/3 次运行 ===\n")
wandb.agent(sweep_id, function=train, count=1) # 每次只跑1个
time.sleep(3) # 间隔3秒
而在wandb的后台中,这三次 run 被整理到同一个 sweep 中,便于互相比较。